Новые книги
 Монография посвящена основным проблемам, возникающим при разработке и формированию региональных брендов. Подробно анализируется теория и методология брендинга. Представлен механизм формирования брендинга регионального уровня как маркетинговой стратегии развития региона. Монография может быть полезна исследователям в области брендинговых технологий, преподавателям, студентам, аспирантам, а также широкому кругу читателей. Монография посвящена основным проблемам, возникающим при разработке и формированию региональных брендов. Подробно анализируется теория и методология брендинга. Представлен механизм формирования брендинга регионального уровня как маркетинговой стратегии развития региона. Монография может быть полезна исследователям в области брендинговых технологий, преподавателям, студентам, аспирантам, а также широкому кругу читателей. |

Часть 3. Аппаратная реализация нейровычислителей
Введение Рассмотрев в предыдущих разделах основы нейроматематики и элеентную базу неровычислителей остановимся более подробнее на анализе структурно-функционального построения нейровычислительных.
Как было отмечено в первой части обзора, нейрокомпьютер - это вычислительная система с MSIMD архитектурой, т.е. с параллельными потоками одинаковых команд и множественным потоком данных. На сегодня можно выделить три основных направления развития вычислительных систем с массовым параллелизмом (ВСМП):
Как отмечено в первой части обзора: нейросетевые системы, реализованные на аппаратных платформах первого направления (пусть и мультипроцессорных) будем относить к нейроэмуляторам - т.е. системам реализующим типовые нейрооперации (взвешенное суммирование и нелинейное преобразование) на программном уровне. Нейросетевые системы, реализованные на аппаратных платформах второго и третьего направления в виде плат расширения стандартных вычислительных систем (1-го направления) - будем называть нейроускорителями и системы, реализованные на аппаратной платформе третьего направления в виде функционально законченных вычислительных устройств, следует относить к нейрокомпьютерам (все операции выполняются в нейросетевом логическом базисе). Нейроускорители можно разделить на два класса "виртуальные" (вставляемых в слот расширения стандартного РС) и "внешние" (соединяющиеся с управляющей Host ЭВМ по конкретному интерфейсу или шине) [2-5]. Рассотрим принципы реализации и основные структурно-функциональные особенности нейровычислителей второго и третьего типа на конкретных примерах.
Нейроускорители на базе ПЛИС. Построение нейровычислителей на базе ПЛИС с одной стороны позволяет гибко реализовать различные нейросетевые парадигмы, а с другой сопряжено с большии проблемами разводки всех необходиых межсоединений. Выпускаемые в настоящее время ПЛИС имеют различные функциональные возожности (с числом вентилей от 5 до 100 тысяч). Нейровычислители на базе ПЛИС - как правило позиционируются как гибкие нейровычислительные систеы для научно-исследовательских целей и елкосерийного производства. Для построения более производительных и эффективных нейровычислителей как правило требуется применение сигнальных процессоров.
Вопросам создания нейровычислителей на ПЛИС посвящено большое число работ, представленных на прошедшей выставке "Нейрокомпьютеры и их применение". Мы, в качестве примера, рассмотрим нейровычислитель созданный в НИИ Систеных исследований (РАН) [3].
Рис.1. Внешний вид ППВ.
Параллельный перепрограммируемый вычислитель (ППВ) разработан в стандарте VME и реализован на базе перепрограммируемых микросхем семейства 10К фирмы Altera. Вычислитель предназначается для работы в качестве аппаратного ускорителя и является ведомым устройством на шине VME. Он должен включаться в систему как подчиненное устройство основной управляющей ЭВМ (host-машины) с универсальным процессором. Тактовая частота вычислителя 33 МГц [3].
ППВ используется для построения систем распознавания образов на основе обработки телевизионной, тепловизионной и другой информации, а также систем, основанных на реализации алгоритмов с пороговыми функциями и простейшими арифметическими операциями и позволяет добиться значительной скорости вычислений.
Вычислитель состоит из следующих функциональных блоков [3]:
Схема управления используется для управления БВЭ и потоками данных в вычислителе и представляет собой простейший RISC процессор. Структура и набор команд процессора могут изменяться в зависимости от типа решаемой задачи.
БВЭ используются для выполнения простейших арифметических операций типа суммирования, вычитания, умножения и вычисления пороговых функций. Так как БВЭ реализованы на перепрограммируемых микросхемах, их архитектура может изменяться. Архитектура БВЭ для различных алгоритмов может отличаться, но обычно легко реализуются путем комбинации библиотечных функций, компиляции их при помощи САПР (типа MaxPlus) и загрузки файла конфигурации в выбранный БВЭ.
Рис.2. Структурная схема ППВ [3].
Два массива локальной статической памяти собраны из 8 микросхем статической памяти емкостью 0,5 Мбайт, имеют размер 4Мбайт и организованы как массив 512К 8-байтовых слов. Массивы памяти связаны со схемой управления отдельными адресными шинами и могут функционировать независимо друг от друга. Память предназначена для хранения общих коэффициентов, а также промежуточных результатов вычислений или окончательных результатов, подготовленных к передаче через контроллер системной шины в центральный процессор или через контроллер E-bus на линк-порты.
Связь нескольких вычислителей между собой или вычислителя с устройством оцифровки изображения, при наличии у устройства оцифровки соответствующего интерфейса, осуществляется посредством последовательного канала приемников/передатчиков HOTLink фирмы CYPRESS. Управление передачей данных выполняет контроллер внешней шины, который представляет из себя набор 4-х стандартных FIFO и регистров управления и данных. Контроллер шины VME выполняет функцию интерфейса с центральным процессором и является стандартным устройством.
С точки зрения программиста вычислитель можно представить как RISC-процессор (схема управления или управляющий процессор) и шесть векторных процессоров (вычислительных элементов), отрабатывающих SIMD-команды (одна команда для многих данных). Большое количество шин данных, возможность одновременной работы всех БВЭ и выполнение арифметических операций умножения и сложения за один такт позволяет эффективно распараллеливать процесс обработки информации.
Особенностью схемы управления перепрограммируемого вычислителя для систем обработки информации является наличие рабочей команды, управляющей шестью базовыми вычислительными элементами. Команда позволяет одновременно, за один такт, задавать различные режимы функционирования шести базовым вычислительным элементам и инкрементировать адреса обоих массивов памяти на любое число от 0 до 255, хранимое в регистрах инкремента, причем каждому массиву соответствует свой регистр. Команда может повторяться любое количество раз в соответствии со значением, хранимым в специальном регистре. Это позволяет выполнять основную команду без потерь на организацию циклов и переходов. Рабочая команда позволяет одновременно запускать оба контроллера локальной памяти, инкрементировать адресные регистры на требуемое значение, выставлять на адресные шины адреса из соответствующих регистров адреса, выставлять на шины управления БВЭ команды из соответствующих регистров БВЭ. Кроме того, рабочая команда осуществляет организацию обмена данными между контроллером внешней шины и локальной памятью.
Таблица 1.
Оценки приведены для:
Pentium-100 при частоте 100 МГц, объем ОЗУ 16 Мбайт; Методика быстрого создания нейровычислителей на ПЛИС приведена в [6]. Основные тенденции в проектировании нейровычислителей на ПЛИС - это увеличение плотности копоновки нейрокристалов за счет уменьшения площади ежсоединений и функциональных узлов цифровых нейронов. Для решения этой задачи находят приенение:
Нейроускорители на базе каскадного соединения сигнальных процессоров Такие нейровычислители представляют собой мультипроцессорные системы с возможностью параллельной обработки, что позволяет реализовывать на их основе нейровычислительные системы, в структуре которых можно выделить две основные части:
Остановимся на особенностях аппаратной реализации нейровычислителя (НВ) с возможностью параллельной обработки, реализующие элементы нейросети.
Рис.3. Обобщенная функциональная схема виртуального НВ.
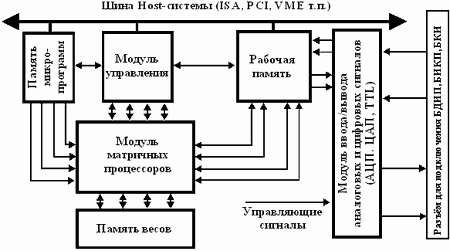
В основе построения НВ данного типа лежит использование сигнальных процессоров, объединенных между собой согласно определенной архитектуры, которая обеспечивает параллельность выполнения вычислительных операций. Как правило, такие НВ строятся на основе гибкой модульной архитектуры, которая обеспечивает простоту конфигурации системы и наращиваемость вычислительной мощности путем увеличения числа процессорных модулей или применения более производительных сигнальных процессоров (рис.3.). НВ данного типа реализуются в основном на базе несущих модулей стандартов ISA, PCI, VME. Основными их функциональными элементами являются модуль матричных сигнальных процессоров (МСП), рабочая память, память программ, модуль обеспечения ввода/вывода сигналов (включающий АЦП, ЦАП и TTL линии), а также модуль управления, который может быть реализован на основе специализированного управляющего сигнального процессора (УП), на основе ПЛИС или иметь распределенную структуру, при которой функции общего управления распределены между МСП.
Для построения НВ данного типа наиболее перспективным является использование сигнальных процессоров с плавающей точкой ADSP2106x, TMS320C4x,8x, DSP96002 и др.
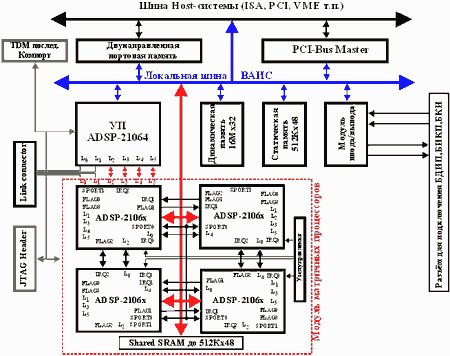
Типовая структурная схема реализации НВ на основе сигнальных процессоров ADSP2106x приведена на рис.4. [5]. В её состав включены один управляющий сигнальный процессор для осуществления функций общего управления, и до восьми процессоров осуществляющих параллельные вычисления согласно заложенным алгоритмам (матричные сигнальные процессоры).
Управляющий и матричные процессоры образуют кластер процессоров с общей шиной и ресурсами разделяемой памяти. Обмен информацией между управляющим процессором, матричными процессорами, Host-ЭВМ и внешней средой осуществляется посредством портов ввода/вывода. Для тестирования и отладки предназначен отладочный JTAG-порт. Так, в случае использования четырех МСП, обмен информацией между ними и УП осуществляется посредством четырех связанных портов ADSP2106x, по два связанных порта УП и модуля МСП выводятся на внешние разъемы для обеспечения связи с внешними устройствами. Имеется 12 внешних линков, а по 3 линка каждого из МСП предназначены для внутримодульного межпроцессорного обмена. Синхронизация работы системы может осуществляться как от внутренних кварцевых генераторов, так и от внешних генераторов. Активизация вычислений программная или внешняя.
Для ввода/вывода и АЦ/ЦА преобразований сигналов предназначен специализированный модуль, который включает в себя: универсальный цифровой TTL порт, АЦП, ЦАП, узел программируемых напряжений для смещения шкал АПЦ и установки порога срабатывания стартовых компараторов, узел фильтрации выходных аналоговых сигналов, подсистему тестирования, узел синхронизации и управления, буферную память FIFO. Первоначальная загрузка осуществляется по Host-интерфейсу или по линкам. Управляющий интерфейс любого МСП позволяет управлять процессорным сбросом и прерываниями, его идентификационным номером и т.п.
Рис.4. Реализация НВ на основе ADSP2106x
Такая архитектура НВ обеспечивает выполнение операций ЦОС в реальном времени, ускорение векторных вычислений, возможность реализации нейросетевых алгоритмов с высоким параллелизмом выполнения векторных и матричных операций.
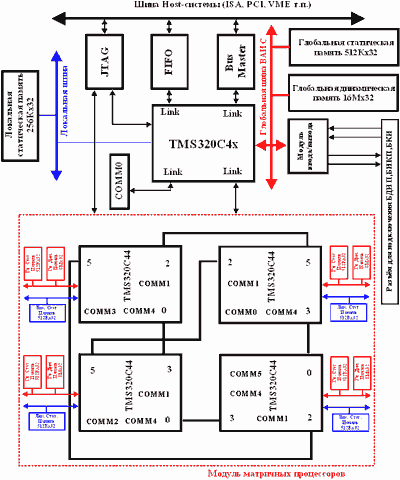
Структурная схема НВ на основе сигнальных процессоров TMS320C4x представлена на рис.5. Несколько DSP, входящих в структуру НВ образуют распределенную вычислительную структуру из процессорных модулей, соединенных между собой высокоскоростными портами. Данный вариант реализации НВ может быть построен с использованием от двух до восьми сигнальных процессоров.
рис.5. Структура НВ на основе TMS320C4x.
При использовании двух параллельных 32-разрядных DSP TMS320C40 обмен информацией при реализации нейросетевых алгоритмов осуществляется с помощью шести связанных портов с пропускной способностью в 30 Мб/c и каналов DMA каждого из процессоров. Поддерживая параллельную независимую работу, подсистема DMA и процессор обеспечивают параллельный обмен информацией со скоростями до 560 Мб/c. При помощи высокоскоростных портов возможна реализация на основе данных DSP таких архитектур, как: кольца, иерархические деревья, гиперкуб и т.п. Каждая из локальных шин TMS320C40 обеспечивает обмен информации на скоростях до 120 Мбайт/с.
Процессорные модули функционируют независимо и при необходимости объединяются посредством связанных портов. Функции обмена, управления процессорными модулями, прерываниями и каналами DMA реализуют ПЛИС, например фирмы Xilinx. Применение в НВ динамических реконфигурируемых структур (нейросети со структурной адаптацией) и использование последних ПЛИС семейств хС2ххх-хС4ххх (фирмы Xinlinx) или аналогичных, требует минимизации времени на реконфигурацию ПЛИС, которые чаще всего программируются в режимах Master Serial и Peripherial. Основной недостаток при использовании данных режимов перепрограммирования заключается в зависимости процесса переконфигурации ПЛИС от встроенного тактового генератора. Минимальные потери времени возможно получить при проведении переконфигурации ПЛИС в режиме Slave Serial, в котором внутренний тактовый генератор отключен, а синхронизация осуществляется посредством внешних синхросигналов. Реконфигуратор ПЛИС выполняется в виде специализированной микросхемы (например, XC2018-84pin-50MHz, XC3020-68pin-50MHz).
Подсистема хранения информации включает модули локальной статической (до 256Кх32) и динамической памяти (до 8Мх32) на каждый из процессоров и глобальной статической памяти (до 256Кх32). Host-ЭВМ осуществляет обращение к глобальной статической памяти 16-битными словами в режиме строчных пересылок с авто инкрементированием адреса посредством адресного пространства портов ввода/вывода. Для разрешения возможных конфликтных ситуаций в состав НВ введены арбитры доступа. Дополнительный обмен информацией может быть осуществлен через высокоскоростной коммуникационный порт. Host-ЭВМ имеет возможность прерывать работу любого из процессорных модулей. Подсистема прерываний поддерживает обработку прерываний к любому из DSP при обмене информацией с Host-ЭВМ.
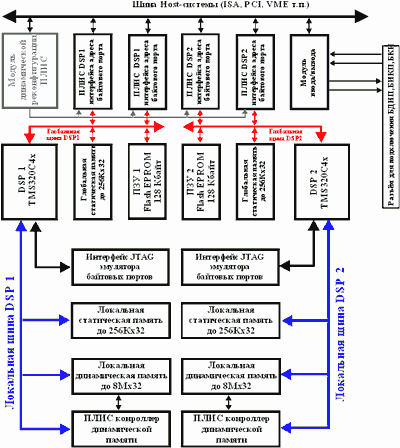
Реализация НВ, блок матричных процессоров которого построен на основе четырех матричных TMS320C44 с производительностью 60 MFLOPS, представляет собой распределенную вычислительную структуру из процессорных модулей с производительностью до 960 MFLOPS, соединенных между собой высокоскоростными портами Структура НВ включает в себя УП (TMS320C44), четыре МСП (TMS320C44), статическую память (до 512Кх32), динамическую память (до 16Мх32) и интерфейсные средства для обмена с внешней средой (рис.4.). Используемый процессор имеет две независимые шины: глобальную и локальную со скоростью обмена до 240 Мбайт/c и четыре параллельных байтовых порта с пропускной способностью 30 Мбайт/с. Коммуникационные порты обеспечивают проведение межпроцессорного обмена с минимальной нагрузкой на микропроцессорное ядро, для чего используются соответствующие контроллеры DMA для каждого из портов. Каждый из портов обеспечивает передачу информации со скоростью до 20 Мбайт/c, что позволяет достигать пиковой производительности по всем портам около 120 Мбайт/с.
Четыре процессорных модуля функционируют на плате независимо. Обмен информации между ними осуществляется посредством байтового порта. Коммуникационные порты и каналы DMA обеспечивают разнообразные возможности высокоскоростного обмена. Host-ЭВМ имеет возможность прерывать работу любого из процессорных модулей. Для использования специализированного многооконного отладчика задач ЦОС фирмы Texas Instruments в структуру НВ вводится JTAG интерфейс. Загрузка программ и данных, обмен данными между НВ и Host-ЭВМ осуществляется через высокоскоростной коммуникационный порт, который имеет FIFO буфера в обоих направлениях. Узлы ввода/вывода подключаются через глобальную шину с пропускной способностью до 100 Мбайт/c. Каналы связи с Host-ЭВМ полностью удовлетворяют стандарту ТIM-40, разработанного консорциумом под руководством Texas Instruments. Внутренняя структура интерфейса определяется загруженной в ПЛИС конфигурацией.
Рассмотренные варианты НВ обеспечивают выполнение ЦОС и нейроалгоритмов в реальном масштабе времени, ускорение векторных и матричных вычислений, по сравнению с традиционными вычислительными средствами в несколько раз и позволяют реализовывать нейросеть с числом синапсов до нескольких миллионов.
Рис.6. Структура НВ на основе TMS320C44
Еще больше повысить производительность НВ данного типа можно при использовании одного из самых мощных на сегодня сигнальных процессоров - TMS320C80, TMS320C6ххх фирмы Texas Instruments.
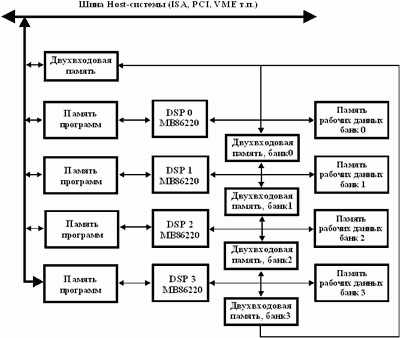
Примером реализации нейровычислителя на DSP фирмы Моторолла является нейровычислитель NEURO TURBO фирмы Fujitsu. Он реализован на основе 4-х связанных кольцом 24-разрядных DSP с плавающей точкой МВ86220 (основные параметры: внутренняя точность 30 разрядов, машинный цикл 150 нс., память программ-25Кслов х2 (внутренняя), 64К слов х4 (внешняя), технология изготовления КМОП 1,2 мкм). Активационная функция нейронов ограничивается в диапазоне от 0 до 1, а возможные значения входов не превышают 16 разрядов, что обуславливает достаточную точность при 24-х разрядной архитектуре. Построение нейрокомпьютера на основе кольцевой структуры объединения DSP позволяет снизить аппаратные затраты на реализацию подсистемы централизованного арбитража межпроцессорного взаимодействия.
Нейрокомпьютер NEURO TURBO (рис.7) состоит из четырех DSP, связанных друг с другом посредством двухпортовой памяти. Каждый из DSP может обращаться к двум модулям такой памяти (емкостью 2К слов каждая) и к рабочей памяти (РП) (емкостью 64К слов х4 Банка) в своем адресном пространстве. Вследствие того что доступ к двухпортовой памяти осуществляется случайным образом одним из соседних DSP, то передача данных между ними происходит в асинхронном режиме. Рабочая память используется для хранения весовых коэффициентов, данных и вспомогательной информации. Для успешной работы НС необходимо получение сверток во всех элементарных нейронных узлах. Кольцевая структура объединения DSP обеспечивает конвейерную архитектуру свертки, причем передача данных по конвейеру осуществляется посредством ДПП. После того как DSP загружает данные из одной ДПП, он записывает результаты своей работы в смежную ДПП, следовательно, кольцевая архитектура параллельной обработки обеспечивает высокую скорость операции с использованием относительно простых аппаратных решений.
Для выполнения функций общего управления используется Host-ЭВМ на основе обычной вычислительной системы. Обмен данными между нейроплатой и Host-ЭВМ через центральный модуль ДПП. Загрузка программ в DSP осуществляется посредством памяти команд для каждого DSP. Следовательно, его архитектура полностью соответствует параллельной распределенной архитектуре типа MIMD. Пиковая производительность системы 24 MFLOPS.
Рис.7. Структура нейрокомпьютера NEURO TURBO (фирмы Fujitsu)
Для реализации модели НС иерархического типа фирмой Fujitsu выпущена нейроплата на основе DSP МВ86232, с собственной памятью до 4 Мб, что позволяет осуществлять моделирование НС, содержащей более 1000 нейронов. Структура НС включает в себя входной, промежуточный и выходной уровни (наибольшее число скрытых слоев - два (ограничение по памяти)). Для обучения нейрокомпьютера используются оригинальные фирменные алгоритмы: алгоритм виртуального импеданса, алгоритм скорректированного обучения и алгоритм расширенного обучения.
Каждая из рассмотренных типовых структур реализации НС может быть промоделирована на основе рассмотренных выше вариантов построения мультипроцессорных НВ. Так, для НВ на основе TMS320C4x при реализации какой-либо из рассмотренных архитектур (кольцо, иерархическое дерево, гиперкуб и т.п.) достаточно только изменить назначения коммуникационных портов, что обеспечивает гибкость и масштабируемость при исследовании и разработках нейросетевых систем различной архитектуры.
Если приведенное выше обобщенное описание реализации нейровычислительных систем Вас еще не утомило и Вы горите желанием попробовать что-то реализовать своими руками, то перед Вами встанет вопрос, а где взять "железо". Конечно, если вы работаете в крупном НИИ, то можно сделать и самим, а если вам необходимо уже готовое изделие? На рынке высокопараллельных вычислителей Москвы можно выделить следующие отечественные фирмы: во-первых, это АОЗТ "Инструентальные системы" (http://www.insys.ru) и НТЦ "Модуль" (http://www.mudule.ru), которые имеют целую линейку серийно производимых высокопараллельных вычислителей, во-вторых, это фирмы AUTEX Ltd (http://www.autex.ru), L-Card Ltd (http://www.lcard.ru) - производящие высокопараллельные вычислители , как правило под заказ на базе микропроцессоров Analog Devices, и фирма Scan (а точнее Scan Engeeniring Telecom (Воронеж)) - представляющая высокопараллельные вычислители на базе DSP фирмы Texas Instruments (http://www.scan.ru). Проанализируем продукцию некоторых из данных фирм в области высокопараллельных вычислителей на конкретных примерах.
[Назад][Содержание][Вперед]Часть 3. Аппаратная реализация нейровычислителей
№ Наименование направления Описание 1 ВСМП на базе каскадного соединения универсальных SISD, SIMD, MISD микропроцессоров. Элементная база - универсальные RISC или CISC процессоры: Intel, AMD, Sparc, Alpha, Power PC, MIPS и т.п. 2 На базе процессоров с распараллеливанием на аппаратном уровне. Элементная база - DSP процессоры: TMS, ADSP, Motorola, ПЛИС. 3 ВСМП на специализированной элементной базе Элементная база от специализированных однобитовых процессоров до нейрочипов.


Название алгоритма Pentium-100, с PentiumII-333, с Ultra SPARC, c ППВ, с Свертка с ядром 4х4 3) 0.65 0.11 0.76 0.02 Медианный Фильтр 1.97 0.49 0.75 0.001 Повышение контрастности 0.51 0.13 1.31 0.004 Прямое поточечное сравнение с маской 32х32 4) 43.78 7.14 58.89 0.142 Поиск локальных неоднородностей 32х32 0.120 0.028 0.146 0.032 Умножение матрицы на матрицу 8.61 0.60 12.31 0.011
Pentium-333 при частоте 350 МГц, объем ОЗУ 128 Мбайт;,br>
UltraSPARC при частоте 200 МГц, объем ОЗУ 64 Мбайт;,br>
Вычислителя при частоте 33 МГц.