Новые книги
 Хорошее программное обеспечение создается людьми. Так же как и плохое. Именно поэтому основная тема этой книги — не аппаратное и не программное обеспечение, а человеческий фактор в программировании (peopleware). Первое издание «Constantine on Peopleware» признано классическим трудом в области информационных технологий. Новая книга Ларри Константина включает все 52 легендарные статьи из предыдущей книги и 25 новых эссе. Хорошее программное обеспечение создается людьми. Так же как и плохое. Именно поэтому основная тема этой книги — не аппаратное и не программное обеспечение, а человеческий фактор в программировании (peopleware). Первое издание «Constantine on Peopleware» признано классическим трудом в области информационных технологий. Новая книга Ларри Константина включает все 52 легендарные статьи из предыдущей книги и 25 новых эссе.Peopleware охватывает все аспекты, связанные с ролью людей в разработке программного обеспечения. Это качество и продуктивность, модели и методы, динамика поведения коллектива, руководство проектами, разработка интерфейсов и взаимодействие между человеком и компьютером, психология и процессы мышления. В данное издание включены два новых раздела, посвященных организационной культуре и юзабилити программных продуктов. Название оригинала на английском языке: The Peopleware Papers by Larry L. Constantine |
 Биткойн – это пиринговая платежная система и финансовая технология, ломающая многие привычные представления о деньгах и их роли в обществе. В этой книге представлена невероятная история о том, как идея подобной системы, изначально интересная лишь маленькой группке энтузиастов, постепенно привлекла к себе внимание всего мира. Биткойн – это пиринговая платежная система и финансовая технология, ломающая многие привычные представления о деньгах и их роли в обществе. В этой книге представлена невероятная история о том, как идея подобной системы, изначально интересная лишь маленькой группке энтузиастов, постепенно привлекла к себе внимание всего мира.В этой истории принимают участие самые неожиданные персонажи: финский студент и аргентинский миллионер, китайский предприниматель и программист-создатель Netscape, неудавшийся физик, ставший онлайн-наркобароном, и близнецы-плейбои, засудившие главу Facebook, акулы венчурного капитала и руководители крупнейших мировых банков, прокуроры, спецагенты и сенаторы США, ну и конечно, сам отец-основатель Биткойна, известный под псевдонимом Сатоши Накамото. И хотя многих ставит в тупик сама мысль о цифровой валюте, за которой не стоит мощное государство или центробанк, энтузиасты Биткойна во всем мире, от Пекина до Буэнос-Айреса, верят в потенциальную возможность этой финансовой системы стать всемирно признанными деньгами цифровой эпохи. Книга адресована тем, кто интересуется современными финансовыми системами, и в частности, криптовалютными технологиями. |
Глава 2. Unicode
Microsoft Windows становится все популярнее, и нам, разработчикам, надо больше ориентироваться на международные рынки. Раньше считалось нормальным, что локализованные версии программных продуктов выходят спустя полгода после их появления в США. Но расширение поддержки в операционной системе множества самых разных языков упрощает выпуск программ, рассчитанных на международные рынки, и тем самым сокращает задержки с началом их дистрибуции.
В Windows всегда были средства, помогающие разработчикам локализовать свои приложения. Программа получает специфичную для конкретной страны информацию (региональные стандарты), вызывая различные функции Windows, и узнает предпочтения пользователя, анализируя параметры, заданные в Control Panel. Кроме того, Windows поддерживает массу всевозможных шрифтов.
Я решил
переместить эту главу в начало книги, потому что вопрос о поддержке Unicode стал
одним из основных при разработке любого приложения. Проблемы, связанные с
Unicode, обсуждаются почти в каждой главе; все программы-примеры в моей книге
«готовы к Unicode». Тот, кто пишет программы для Microsoft Windows 2000 или
Microsoft Windows CE, просто обязан использовать Unicode, и точка. Но если Вы
разрабатываете приложения для Microsoft Windows 98, у Вас еще есть выбор. В
этой
главе мы поговорим и о применении Unicode в Windows 98.
Наборы символов
Настоящей проблемой при локализации всегда были операции с различными наборами символов. Годами, кодируя текстовые строки как последовательности однобайтовых символов с нулем в конце, большинство программистов так к этому привыкло, что это стало чуть ли не второй их натурой. Вызываемая нами функция strlen возвращает количество символов в заканчивающемся нулем массиве однобайтовых символов. Но существуют такие языки и системы письменности (классический пример — японские иероглифы), в которых столько знаков, что одного байта, позволяющего кодировать не более 256 символов, просто недостаточно. Для поддержки подобных языков были созданы двухбайтовые наборы символов (double-byte character sets, DBCS).
Одно- и двухбайтовые наборы символов
В двухбайтовом наборе символ представляется либо одним, либо двумя байтами. Так, для японской каны, если значение первого байта находится между 0x81 и 0x9F или между 0xE0 и 0xFC, надо проверить значение следующего байта в строке, чтобы определить полный символ. Работа с двухбайтовыми наборами символов — просто кошмар для программиста, так как часть их состоит из одного байта, а часть — из двух.
Простой вызов функции strlen не дает количества символов в строке — она возвращает только число байтов. В ANSI-библиотске С нет функций, работающих с двухбайтовыми наборами символов. Но в аналогичную библиотеку Visual C++ включено множество функций (типа _mbslen), способных оперировать со строками мультибайтовых (как одно-, так и двухбайтовых) символов.
Для работы с DBCS-строками в Windows предусмотрен целый набор вспомогательных функций:
|
Функция |
Описание |
|
PTSTR CharNext (PCTSTR pszCurrentChar); |
Возвращает адрес следующего символа в строке |
|
PTSTR CharPrep(PCTSTR pszStart, PCTSTR pszCurrentChar); |
Возвращает адрес предыдущего символа в строке |
|
BOOL IsDBCSLeadByte (BYTE bTestChar); |
Возвращает TRUE, если данный байт — первый в DBCS-символе |
Функции
CharNext и CharPrev появоляют «перемещаться» по двухбайтовой
строке
единовременно на 1 символ вперед или назад, a IsDBCSLeadByte
возвращает TRUE, если
переданный ей байт — первый в двухбайтовом
символе
Хотя эти
функции несколько облегчают работу с DBCS-строками, необходимость
в ином
подходе очевидна. Перейдем к Unicode
Unicode: набор широких символов
Unicode — стандарт, первоначально разработанный Apple и Xerox в 1988 г В 1991 г был создан консорциум для совершенствования и внедрения Unicode В него вошли компании Apple, Compaq, Hewlett-Packard, IBM, Microsoft, Oracle, Silicon Graphics, Sybase, Unisys и Xcrox. (Полный список компаний — членов консорциума см на www.Unicode.org.) Эта группа компаний наблюдает за соблюдением стандарта Unicode, описание которого Вы найдете в книге Tbe Unicode Standard издательства Addison-Wesley (ее электронный вариант можно получить на том же www.Unicode.org).
Строки в Unicode просты и логичны. Все символы в них представлены 16-битными значениями (по 2 байта на каждый). В них нет особых байтов, указывающих, чем является следующий байт — частью того же символа или новым символом. Это значит, что прохождение по строке реализуется простым увеличением или уменьшением значения указателя. Функции CharNext, CharPrev и lsDBCSLeadByte больше не нужны.
Так как каждый символ — 16-битное число, Unicode позволяет кодировать 65 536 символов, что более чем достаточно для работы с любым языком. Разительное отличие от 256 знаков, доступных в однобайтовом наборе!
В настоящее
время кодовые позиции определены для арабского, китайского, греческого,
еврейского, латинского (английского) алфавитов, а также для кириллицы
(русского), японской каны, корейского хантыль и некоторых других алфавитов,
Кроме того, в набор символов включено большое количество знаков препинания,
математических и технических символов, стрелок, диакритических и других знаков.
Все
вместе они занимают около 35 000 кодовых позиций, оставляя простор для
будущих расширений
Эти 65 536 символов разбиты на отдельные группы Некоторые группы, а также включенные в них символы показаны в таблице
1 Кодовая позиция (code point) — позиция знака в наборе символов.
|
16-битный код |
Символы |
16-битный код |
Символы |
|
0000-007F |
ASCII |
0300-U36F |
Общие диакритические |
|
0080-00FF |
Символы Latin 1 |
0400-04FF |
Кириллица |
|
0100-017F |
Европейские латинские |
0530-058F |
Армянский |
|
01 80-01FF |
Расширенные латинские |
0590-05FF |
Еврейский |
|
0250-02AF |
Стандартные фонетические |
0600-06FF |
Арабский |
|
02BO-02FF |
Модифицированные литеры |
0900-097F |
Деванагари |
Около 29 000 кодовых позиций пока не заняты, но зарезервированы на будущее. Примерно 6 000 позиций оставлено специально для программистов (на их усмотрение).
Почему Unicode?
Разрабатывая приложение, Вы определенно должны использовать преимущества Unicode. Даже ссли Вы пока не собираетесь локализовать программный продукт, разработка с прицелом на Unicode упростит эту задачу в будущем. Unicode также позволяет:
- легко обмениваться данными на разных языках;
- распространять единственный двоичный EXE- или DLL-файл, поддерживающий все языки;
- увеличить эффективность приложений (об этом мы поговорим чуть позже).
Windows 2000 и Unicode
Windows 2000 — операционная система, целиком и полностью построенная на Unicode. Все базовые функции для создания окон, вывода текста, операций со строками и т. д. ожидают передачи Unicode-строк. Если какой-то функции Windows передается ANSI-строка, она сначала преобразуется в Unicode и лишь потом передается операционной системе. Если Вы ждете результата функции в виде ANSI-строки, операционная система преобразует строку — перед возвратом в приложение - из Unicode в ANSI. Все эти преобразования протекают скрытно от Вас, но, конечно, на них тратятся и лишнее время, и лишняя намять.
Например, функция CreateWindowEx, вызываемая с ANSI-строками для имени класса и заголовка окна, должна, выделив дополнительные блоки памяти (в стандартной куче Вашего процесса), преобразовать эти строки в Unicode и, сохранив результат в выделенных блоках памяти, вызвать Unicode-версию CreateWindowEx.
Для функций, заполняющих строками выделенные буферы, системе — прежде чем программа сможет их обрабатывать — нужно преобразовать строки из Unicode в ANSI. Из-за этого Ваше приложение потребует больше памяти и будет работать медленнее. Поэтому гораздо эффективнее разрабатывать программу, с самого начала ориентируясь на Unicode.
Windows 98 и Unicode
Windows 98 — не совсем новая операционная система. У нее «16-разрядное наследство, которое не было рассчитано на Unicode. Введение поддержки Unicode в Windows 98 было бы слишком трудоемкой задачей, и при разработке этой операционной системы от нее отказались. По этой причине вся внутренняя обработка строк в Windows 98, как и у ее предшественниц, построена на применении ANSI.
и все же Windows 98 допускает работу с приложениями, обрабатывающими символы и строки в Unicode, хотя вызов функций Windows при этом заметно усложняется. Например, если Бы, обращаясь к CreateWindowEx, передаете ей ANSI-строки, вызов проходит очень быстро — не требуется ни выделения буферов, ни преобразования строк. Но для вызова CreateWindowEx с Unicode-строками Вам придется самому выделять буферы, явно вызывать функции, преобразующие строки из Unicode в ANSI, обращаться к CreateWindowEx, снова вызывать функции, преобразующие строки — на этот раз ил ANSI в Unicode, и освобождать временные буферы. Так что в Windows 98 работать с Unicode не столь удобно, как в Windows 2000. Подробнее о преобразованиях строк в Windows 98 я расскажу в конце главы.
Хотя
большинство Unicode-функций в Windows 98 ничего не делает, некоторые
все же
реализованы Вот они:
- EnumResourceLanguagesW
- EnumResourceNamesW
- EnumResourceTypesW
- ExtTextOutW
- FindResourceW
- FindRcsourceExW
- GetCharWidthW
- GetCommandLineW
- GetTextExtentPoint32W
- GetTexiExtentPolntW
- lstrlenW
- MessageBoxExW
- MessageBoxW
- TextOutW
- WideCharToMultiByte
- MuitiByteToWideChar
К сожалению, многие из этих функций в Windows 98 работают из рук вон плохо. Одни не поддерживают определенные шрифты, другие повреждают область динамически распределяемой памяти (кучу), третьи нарушают работу принтерных драйверов и т. д. С этими функциями Вам придется здорово потрудиться при отладке программы. И даже это еще не значит, что Вы сможете устранить все проблемы.
Windows CE и Unicode
Операционняя система Windows CE создана для небольших вычислительных устройств — бездисковых и с малым объемом памяти. Вы вполне могли бы подумать, что Microsoft, раз уж эту систему нужно было сделать предельно компактной, в качестве «родного» набора символов выберет ANSI. Но Microsoft поступила дальновиднее. Зная, что вычислительные устройства с Windows CE будут продаваться по всему миру, там решили сократить затраты на разработку программ, упростив их локализацию. Поэтому Windows CE полностью поддерживает Unicode.
Чтобы не увеличивать ядро Windows CE, Microsoft вообще отказалась от поддержки ANSI-функций Windows. Так что, ссли Вы пишете для Windows CE, то просто обязаны разбираться в Unicode и использовать его во всех частях своей программы.
В чью пользу счет?
Для тех, кто ведет счет в борьбе Unicode против ANSI, я решил сделать краткий обзор История Unicode в Microsoft:
- Windows 2000 поддерживает Unicode и ANSI — Вы можете использовать любой стандарт;
- Windows 98 поддерживает только ANSI — Вы обязаны программировать в расчете на ANSI;
- Windows CE поддерживает только Unicode — Вы обязаны программировать в расчете на Unicode.
Несмотря на то что Microsoft пытается облегчить написание программ, способных работать на всех трех платформах, различия между Unicode и ANSI все равно создают проблемы, и я сам не раз с ними сталкивался. Не поймите меня неправильно, но Microsoft твердо поддерживает Unicode, поэтому я настоятельно рекомендую переходить именно на этот стандарт. Только имейте в виду, что Вас ждут трудности, на преодоление которых потребуется время. Я бы посоветовал применять Unicode и, если Вы работаете в Windows 98, преобразовывать строки в ANSI лишь там, где без этого нс обойтись.
Увы, есть еще одна маленькая проблема, о которой Вы должны знать, — СОМ.
Unicode и СОМ
Когда Microsoft переносила СОМ из 16-разрядной Windows на платформу Win32, руководство этой компании решило, что все методы СОМ-интсрфейсов, работающие со строками, должны принимать их только в Unicode Это было удачное решение, так как СОМ обычно используется для того, чтобы компоненты могли общаться друг с другом, a Unicode позволяет легко локализовать строки.
Eсли Вы разрабатываете программу для Windows 2000 или Windows СЕ и при этом используете СОМ, то выбора у Вас просто нет. Применяя Unicode во всех частях программы, Вам будет гораздо проще обращаться и к операционной системе, и к COM объектам.
Если Вы пишете для Windows 98 и тоже используете СОМ, то попадаете в затруднительное положение. СОМ требует строк в Unicode, а большинство функций операционной системы — строк в ANSI. Это просто кошмар! Я работал над несколькими такими проектами, и мне приходилось писать прорву кода только для того, чтобы гонять строки из одного формата в другой.
Как писать программу с использованием Unicode
Microsoft разработала Windows API так, чтобы как можно меньше влиять на Ваш код. В самом деле, у Вас появилась возможность создать единственный файл с исходным кодом, компилируемый как с применением Unicode, так и без него, — достаточно определить два макроса (UNICODE и _UNICODE), которые отвечают за нужные изменения.
Unicode и библиотека С
Для использования Unicode-строк были введены некоторые новые типы данных. Стандартный заголовочный файл String.h модифицирован в нем определен wchar_t — тип данных для Unicode-символа
typedef unsigned short wchar_t
Если Вы хотите, скажем, создать буфер для хранения Unicode-строки длиной до 99 символов с нулевым символом в конце, поставьте оператор:
wchar_t szBuffer[100];
Он создает массив из ста 16-битных значений. Конечно, стандартные функции библиотеки С для работы со строками вроде strcpy, strchr и strcat оперируют только с ANSI-строками — они не способны корректно обрабатывать Unicode-строки. Поэто
му в ANSI С имеется дополнительный набор функций. На рис. 2-1 приведен список строковых функций ANSI C и эквивалентных им Unicode-функций.
char * strcat(char *, const char *);
wchar_t * wcscat(wchar_t *, const wchar t *);
char * strchr(const char *, int);
wchar_t * wcschr(const wchar_t *, wchar_t);
int strcmp(const char *, const char *);
int wcscmp(const wchar_t *, const wchar_t *);
char * strcpy(char *, const char *);
wchar_t * wcscpy(wchar_t *, const wchar_t *);
size_t strlen(const char *);
size_t wcslen(const wchar_t *);
Рис. 2-1. Строковые функции ANSI C и их Unicode-аналоги
Обратите внимание, что имена всех новых функций начинаются с wcs — это аббревиатура wide character set (набор широких символов) Таким образом, имена Unicode-функций образуются простой заменой префикса str соответствующих ANSI-функций на wcs.
NOTE:
Один очень важный момент, о котором многие забывают, заключается в том, что библиотека С, предоставляемая Microsoft, отвечает стандарту ANSI. A он требует, чтобы библиотека С поддерживала символы и строки в Unicode Это значит, что Вы можете вызывать функции С для работы с Unicode-символами и строками даже при работе в Windows 98. Иными словами, функции wcscat, wcslen, wcstok и т. д. прекрасно работают и в Windows 98; беспокоиться нужно за функции операционной системы.
Код, содержащий явные вызовы str- или wcs-функций, просто так компилировать с использованием и ANSI, и Unicode нельзя. Чтобы реализовать возможность компиляции "двойного назначения", замените в своей программе заголовочный файл String.h на TChar.h Он помогает создавать универсальный исходный код, способный задействовать как ANSI, так и Unicode, — и это единственное, для чего нужен файл TChar.h. Он состоит из макросов, заменяющих явные вызовы str- или wcs-функций. Если при компиляции исходного кода Вы определяете _UNICODE, макросы ссылаются на wcs-функции, а в его отсутствие — на str-фупкции
Например, в TChar.h есть макрос _tcscpy. Если Вы включили этот заголовочный файл, но UNlCODE не определен, _tcscpy раскрывается в ANSI-функцию strcpy, а если _UNICODE определен — в Unicode-функцию wcscpy, В файле TChar.h определены универсальные макросы для всех стандартных строковых функций С. При использовании этих макросов вместо конкретных имен ANSI- или Unicode-функций Ваш код можно будет компилировать в расчете как на Unicode, так и на ANSI.
Но, к сожалению, это ещe не все. В файле TChar.h есть дополнительные макросы.
Чтобы объявить символьный массив универсального назначения" (ANSI/Unicode), применяется тип данных TCHAR. Если _UNICODE определен, TCHAR объявляется так:
typedef wchar_L TCHAR;
А если UNICODE не определен, то:
typedef char TCHAR
Используя этот тип данных, можно объявить строку символов как:
TCHAR szString[100];
Можно также определять указатели на строки:
TCHAR *szError = "Error";
Правда, в этом операторе есть одна проблема. По умолчанию компилятор Microsoft С++ транслирует строки как состоящие из символов ANSI, а не Unicode. B итоге этот оператор нормально компилируется, если UNICODE не определен, но в ином случае дает ошибку. Чтобы компилятор сгенерировал Unicode-, a не ANSI-строку, оператор надо переписать так
TCHAR *szFrror = L"Error";
Заглавная буква L перед строковым литералом указывает компилятору, что его надо обрабатывать как Unicode-строку. Тогда, размещая строку в области данных программы, компилятор вставит между всеми символами нулевые байты. Но возникает другая проблема — программа компилируется, только если _UNICODE определен Следовательно, нужен макрос, способный избирательно ставить L перед строковым литералом. Эту работу выполняет макрос _TEXT, также содержащийся в Tchar.h. Если _UNICODE определен, _TEXT определяется как
#define _TEXT(x) L ## x
В ином случае _TEXT определяется следующим образом:
#define _TEXT(x) x
Используя этот макрос, перепишем злополучный оператор так, чтобы его можно было корректно компилировать независимо от того, определен _UNICODE или нет:
TCHAR *szError = _TEXT("Error");
Макрос _TEXT применяется и для символьных литералов. Например, чтобы проверить, является ли первый символ строки заглавной буквой J:
if (szError[0] == _TEXT('J')) {
// первый символ - J
} else {
// первый символ - не J
}
Типы данных, определенные в Windows для Unicode
В
заголовочных файлах Windows определены следующие типы данных.
|
Тип данных |
Описание |
|
WCHAR |
Unicode-символ |
|
PWSTR |
Указатель на Unicode -строку |
|
PCWSTR |
Указатель на стоковую константу в Unicode |
Эти типы данных относятся исключительно к символам и строкам в кодировке Unicode. B заголовочных файлах Windows определены также универсальные (ANSI)
Unicode) типы данных PTSTR и PCTSTR, указывающие — в зависимости от того, определен ли при компиляции макрос UNICODE, — на ANSI или на Unicode-строку
Кстати, на этот раз имя макроса UNICODE не предваряется знаком подчеркивания Дело в том, что макрос _UNICODE используется в заголовочных файлах библиотеки С, а макрос UNICODE — в заголовочных файлах Windows Для компиляции модулей исходного кода обычно приходится определять оба макроса
Unicode- и ANSI-функции в Windows
Я уже говорил, что существует две функции CreateWindowEx одна принимает строки в Umcode, другая — в ANSI Все так, но в действительности прототипы этих функций чуть чуть отличаются
HWND WINAPI CreateWindowExW(
DWORD dwExStyle,
PCWSTR pClassName,
PCWSTR pWindowName,
DWORD dwStyle,
int X,
int Y,
int nWidth,
int nHeight,
HWND hWndParent,
HMENU hHenu,
HINSTANCE hInstance,
PVOID pParam);HWND WINAPI CreatcWindowExA(
DWORD dwExStyle,
PCSTR pClassName,
PCSTR pWindowName,
DWORD dwStyle,
int X
int Y,
int nWidth,
inT nHeight,
HWND hWndParent,
HMENU hMenu,
HINSTANCF hInstance,
PVOID pParam);
CteateWindowExW — это Unicode-версия Буква W в конце имени функции — аббpевиатуpa слова wide (широкий) Символы Unicode занимают по 16 битов каждый, поэтому их иногда называют широкими символами (wide characters) Буква А в конце имени CreateWindoivExA указывает, что данная версия функции принимаетАNSI-строки
Но обычно CreateWmdowExW или CreateWindowExA напрямую не вызывают А обращаются к CreateWindowEx — макросу, определенному в файле WmUser.h
#ifdef UNICODE
#define CreateWindowEx CreateWindowExW
#else
#define CreateWindowEx CreateWindowExA
#endif // UNICODE
Какая именно
версия CreateWindowEx будет вызвана, зависит от того, определен ли UNICODE в
период компиляции. Перенося 1б-разрядное Windows-приложение на платформу Win32.
Вы, вероятно, не станете определять UNICODE. Тогда все вызовы CreateWindowEx
будут преобразованы в вызовы CreateWindowExA — ANSI-версии функции. И перенос
приложения упростится, ведь 16-разрядная Windows работает толь-
ко с
ANSI-версией CreateWindowEx.
В Windows 2000 функция CreateWindowExA — просто шлюз (транслятор), который выделяет память для преобразования строк из ANSI в Unicode и вызывает CreateWindowExW, передавая ей преобразованные строки. Когда CreateWindowExW вернет управление, CrealeWindowExA освободит буферы и передаст Вам описатель окна.
Разрабатывая DLL, которую будут использовать и другие программисты, предусматривайте в ней по две версии каждой функции — для ANSI и для Unicode. В ANSI-версии просто выделяйте память, преобразуйте строки и вызывайте Unicode-версию той же функции. (Этот процесс я продемонстрирую позже.)
В Windows 98 основную работу выполняет CreateWindowExA. В этой операцион ной системе предусмотрены точки входа для всех функций Windows, принимающих Unicode-строки, но функции не транслируют их в ANSi, а просто сообщают об ошибке. Последующий вызов GetLastError дает ERRORCALL_NOT_IMPLEMENTED. Должным образом действуют только ANSI-версии функций. Ваше приложение не будет работать в Windows 98, если в скомпилированном коде присутствуют вызовы "широкосимвольных" функций.
Некоторые функции Windows API (например, WinExec или OpenFile) существуют только для совместимости с 16-разрядными программами, и их надо избегать. Лучше заменить все вызовы WinExec и OpenFile вызовами CreateProcess и CreateFile соответственно. Тем более, что старые функции просто обращаются к новым. Самая серьезная проблема с ними в том, что они не принимают строки в Unicode, при их вызове Вы должны передавать строки в ANSI. С другой стороны, в Windows 2000 у всех новых или пока не устаревших функций обязательно есть как ANSI-, так и Unicode-версия.
Строковые функции Windows
Windows
предлагает внушительный набор функций, работающих со строками. Они похожи на
строковые функции из библиотеки С, например на strcpy и wcscpy. Однако функции
Windows являются частью операционной системы, и многие се компоненты используют
именно их, а нс аналоги из библиотеки С. Я советую отдать предпочтение функциям
операционной системы. Это немного повысит быстродействие Ва-
шего
приложения. Дело в том, что к ним часто обращаются такие тяжеловесные процессы,
как оболочка операционной системы (Explorer.exe), и скорее всего эти функции
будут загружены в память еще до запуска Вашего приложения.
NOTE:
Данные функции доступны в Windows 2000 и Windows 98. Но Вы сможете вызывать их и в более ранних версиях Windows, если установите Internet Explorer версии 4.0 или выше.
По
классической схеме именования функций в операционных системах их имена состоят
из символов нижнего и верхнего регистра и выглядят так; StrCat, StrChr, StrCmp,
StrCpy и т. д. Для использования этих функций включите в программу заголовочный
файл ShlWApi.h. Кроме того, как я уже говорил, каждая строковая функция
существует в двух версиях — для ANSI и для Unicode (например, StrCatA и
StrCatW).
Поскольку это функции операционной системы, их имена автоматически
преобразуются в нужную форму, если в исходном тексте Вашей программы перед ее
сборкой определен UNICODE.
Создание программ, способных использовать и ANSI, и Unicode
Неплохая мысль — заранее подготовить свое приложение к Unicode, даже если Вы пока не планируете работать с этой кодировкой. Вот главное, что для этого нужно:
- привыкайте к тому, что текстовые строки — это массивы символов, а не массивы байтов или значений типа char;
- используйте универсальные типы данных (вроде TCHAR или PTSTR) для текстовых символов и строк;
- используйте явные типы данных (вроде BYTE или PBYTE) для байтов, указателей на байты и буферов данных;
- применяйте макрос _TEXT для определения символьных и строковых литералов;
- предусмотрите возможность глобальных замен (например, PSTR на PTSTR);
- модифицируйте логику строковой арифметики. Например, функции
обычно
принимают размер буфера в символах, а не в байтах Это значит, что вместо
sizeof(szBuffer) Вы должны передавать (sizeof(szBuffer) / sizeof(TCHAR)). Но
блок памяти для строки известной длины выделяется в байтах, а не символах, т.
e. вместо malloc(nCharacters) нужно использовать malloc(nCbaracters
*sizeof(TCHAR)) Из всего, что я перечислил, это запомнить труднее всего — если
Вы ошибетесь, компилятор не выдаст никаких предупреждений.
Разрабатывая программы-примеры для первого издания книги, я сначала написал их так, что они компилировались только с использованием ANSI. Но, дойдя до этой главы (она была тогда в конце), понял, что Unicode лучше, и решил написать примеры, которые показывали бы, как легко создавать программы, компилируемые с применением и Unicode, и ANSI. B конце концов я преобразовал все программы-примеры так, чтобы их можно было компилировать в расчете на любой из этих стандартов.
Конверсия всех программ заняла примерно 4 часа — неплохо, особенно если учесть, что у меня совсем не было опыта в этом деле.
В Windows есть набор функций для работы с Unicode-строками. Эти функции перечислены ниже.
|
Функция |
Описание |
|
lstrcat |
Выполняет конкатенацию строк |
|
lstrcmp |
Сравнивает две строки с учетом регистра букв |
|
lstrcmpi |
Сравнивает две строки без учета регистра букв |
|
lstrcpy |
Копирует строку в другой участок памяти |
|
lstrlen |
Возвращает длину строки в символах |
Они
реализованы как макросы, вызывающие либо Unicode-, либо ANSI-версию функции в
зависимости от того, определен ли UNICODE при компиляции исходного модуля
Например, если UNICODE не определен, lstrcat раскрывается в lstrcatA, определен
— в lstrcatW.
Строковые функции lstrcmp и lstrcmpi ведут себя не так, как их аналоги из библиотеки С (strcmp, strcmpi, wcscmp и wcscmpf), которые просто сравнивают кодовые позиции в символах строк. Игнорируя фактические символы, они сравнивают числовое значение каждого символа первой строки с числовым значением символа второй
строки. Но lstrcmp и lstrcmpi реализованы через вызовы Windows-функции CompareString;
int CompareString(
LCID lcid,
DWORD fdwStyle,
PCWSTR pString1,
int cch1,
PCWSTR pString2,
int cch2);
Она сравнивает две Unicode-строки. Первый параметр задаст так называемый идентификаторлокализации (locale ID, LCID) — 32-битное значение, определяющее конкретный язык. С помощью этого идентификатора CompareString сравнивает строки с учетом значения конкретных символов в данном языке. Так что она действует куда осмысленнее, чем функции библиотеки С.
Когда любая из функций семейства lstrcmp вызывает CompareString, в первом параметре передается результат вызова Windows-функции GetThreadLocale.
LCID GetThreadLocale();
Она возвращает уже упомянутый идентификатор, который назначается потоку в момент его создания.
Второй параметр функции CompareString указывает флаги, модифицирующие метод сравнения строк. Допустимые флаги перечислены в следующей таблице.
|
Флаг |
Действие |
|
NORM_IGNORECASE |
Различия в регистре букв игнорируются |
|
NORM_IGNOREKANATYPE |
Различия между знаками хираганы и катаканы игнорируются |
|
NORM_IGNORENONSPACE |
Знаки, отличные от пробелов, игнорируются |
|
NORM_IGNORESYMBOLS |
Символы, отличные от алфавитно-цифровых, игнорируются |
|
NORM_IGNOREWIDTH |
Разница
между одно- и двухбайтовым представлением одного |
|
SORT_STRINGSORT |
Знаки
препинания обрабатываются так же, как и символы, от- |
Вызывая CompareString, функция lstrcmp передает в параметре fdwStyle нуль, а lstrcmpi — флаг NORM_IGNORECASE. Остальные четыре параметра определяют две строки и их длину. Если cch1 равен -1, функция считает, что строка pString2 завершается нулевым символом, и автоматически вычисляет ее длину. То же относится и к параметрам cch2 wpString2.
Многие функции С-библиотеки с Unicode-строками толком не работают. Так, tolower и toupper неправильно преобразуют регистр букв со знаками ударения. Поэтому для Unicode-строк лучше использовать соответствующие Windows-функции. К тому же они корректно работают и с ANSI-строками.
Первые две функции:
PTSTR CharLower(PTSTR pszStnng);
PTSTR CharUpper(PTSTR pszString);
преобразуют либо отдельный символ, либо целую строку с нулевым символом в конце. Чтобы преобразовать всю строку, просто передайте ее адрес. Но, преобразуя отдельный символ, Вы должны передать его так:
TCHAR cLowerCaseCnr = CharLower((PTSTR) szString("O"));
Приведение типа отдельного символа к PTSTR вызывает обнуление старших 16 битов передаваемого значения, а в его младшие 16 битов помещается сам символ. Обнаружив, что старшие 16 битов этого значения равны 0, функция поймет, что Вы хотите преобразовать не строку, а отдельный символ. Возвращаемое 32-битное зна чение содержит результат преобразования в младших 16 битах.
Следующие две функции аналогичны двум предыдущим за исключением того, что они преобразуют символы, содержащиеся в буфере (который не требуется завершать нулевым символом).
DWORD CharLowerBuff(
PTSTR pszString,
DWORD cchString);DWORD CharUppprRuff(
PTSTR pszString,
DWORD cchString);
Прочие функции библиотеки С (например, isalpba, islowern isupper) возвращают значение, которое сообщает, является ли данный символ буквой, а также строчная она или прописная. В Windows API тоже есть подобные функции, но они учитывают и язык, выбранный пользователем в Control Panel:
BOOL IsCharAlpha(TCHAR ch);
BOOL IsCharAlphaNumeric(TCHAR ch);
BOOL IsCharLower(TCHAR oh);
BOOL IsCharUpper(TCHAR ch);
И последняя группа функций из библиотеки С, о которых я хотел рассказать, — prmtf, Если при компиляции _UNICODE определен, они ожидают передачи всех символьных и строковых параметров в Unicode; в ином случае — в ANSI.
Microsoft ввела в семейство фупкций printf своей С-библиотеки дополнительные типы полей, часть из которых не поддерживается в ANSI C. Они позволяют легко сравнивать и смешивать символы и строки с разной кодировкой. Также расширена функция wsprintf операционной системы. Вот несколько примеров (обратите внимание на использование буквы s в верхнем и нижнем регистре):
char szA[100]; // строковый буфер e ANSI
WCHAR szW[100]; // строковый буфер в Unicode// обычный вызов sprintf: все строки в ANSI
sprintf(szA, "%s", "ANSI Str");// преобразуем строку из Unicode в ANSI
sprintf(szA, "%S", "Unicode Str");// обычный вызов swprintf. все строки в Unicode
swprintf(szW, L"%s", L"Unicode Str");// преобразуем строку из ANSI в Unicode
swprintf(s/W, L"%S", "ANSI Str");
Ресурсы
Компилятор ресурсов генерирует двоичное представление всех ресурсов, используемых Вашей программой. Строки в ресурсах (таблицы строк, шаблоны диалоговых окон, меню и др.) всегда записываются в Unicode Если в программе не определяется макрос UNICODE, Windows 98 и Windows 2000 сами проводят нужные преобразования Например, если при компиляции исходного модуля UNICODE не определен, вызов LoadString на самом деле приводит к вызову LoadStringA, которая читает строку из ресурсов и преобразует ее в ANSI. Затем Вашей программе возвращается ANSI-представление строки
Текстовые файлы
Текстовых
файлов в кодировке Unicode пока очень мало. Ни в одном текстовом файле,
поставляемом с операционными системами или другими программными продуктами
Microsoft, не используется Unicode. Думаю, однако, что эта тенденция изменится в
будущем — пусть даже в отдаленном Например, программа Notepad в Windows 2000
позволяет создавать или открывать как Unicode-, так и ANSI-файлы. Посмотрите
на
ее диалоговое окно Save Аs (рис. 2-2) и обратите внимание на предлагаемые
форматы текстовых файлов.
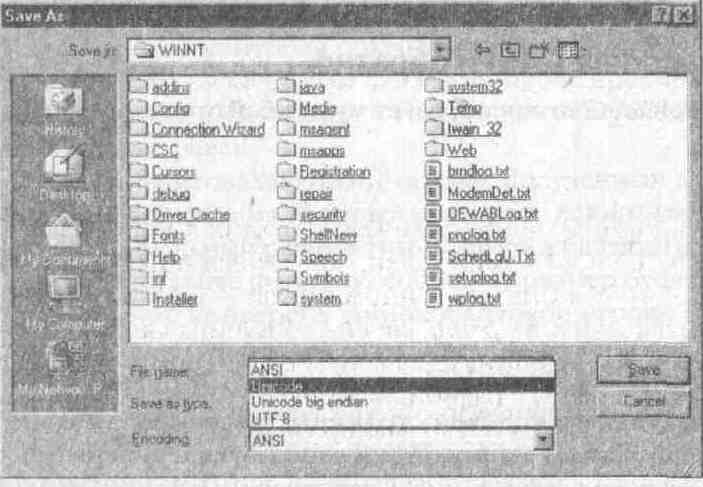
Рис. 2-2. Диалоговое окно Save As программы Notepad в Windows
2000
Многим приложениям, которые открывают и обрабатывают текстовые файлы (например, компиляторам), было бы удобнее, если после открытия файла можно было бы определить, содержит он символы в ANSI или в Unicode. B этом может помочь функция IsTextUnicode
DWORD IsTextUnicode(CONST PVOID pvBuffer, int cb, PINT pResult);
Проблема с
текстовыми файлами в том, что не существует четких и строгих правил относительно
их содержимого. Это крайне затрудняет определение того, содержит файл символы в
ANSI или в Unicode Поэтому IsTextUnicode применяет набор статистических и
детерминистских методов для того, чтобы сделать взвешенное предположение о
содержимом буфера. Поскольку тут больше алхимии, чем точной науки,
нет
гарантий, что Вы не получите неверные результаты от
IsTextUnicode.
Первый ее парамегр, pvBuffer, указывает на буфер, подлежащий проверке. При этом используется указатель типа void, поскольку неизвестно, в какой кодировке данный массив символов.
Параметр сb определяет число байтов в буфере, на который указываетр pvBuffer Так как содержимое буфера не известно, сb - счетчик именно байтов, а не символов. Заметьте: вовсе не обязательно задавать всю длину буфера. Но чем больше байтов проанализирует функция, тем больше шансов получить правильный результат.
Параметр pResult — это адрес целочисленной переменной, которую надо инициализировать перед вызовом функции. Ее значение сообщает, какие тесты должна провести IsTextUnicode. Если pResult равен NULL, функция IsTextUnicode делает все проверки. (Подробнее об этом см. документацию Platform SDK.)
Функция возвращает TRUE, если считает, что буфер содержит текст в Unicode, и FALSE — в ином случае. Да-да, она возвращает именно булево значение, хотя в прототипе указано DWORD. Если через целочисленную переменную, на которую указывает pResuIt, были запрошены лишь определенные тесты, функция (перед возвратом управления) устанавливает ее биты в соответствии с результатами этих тестов.
WINDOWS 98:
В Windows 98 функция IsTextUnicode по сути не реализована и просто возвращает FALSE; последующий вызов GetLastError дает код ошибки ERRORCALL_NOT_IMPLEMENTED.
Применение
функции IsTextUnicode иллюстрирует программа-пример FileRev (см. главу
17).
Перекодировка строк из Unicode в ANSI и обратно
Windows-функция MultiByteToWideChar преобразует мультибайтовые символы строки в широкобайтовые:
int MultiBytoToWideChar(
UINT uCodePage,
DWORD dwFlags,
PCSTR pMultiByteStr,
int cchMultiByte,
PWSTR pWideCharStr,
int cchWideChar);
Параметр uCodePage задает номер кодовой страницы, связанной с мультибайтовой строкой. Параметр dwFlags влияет на преобразование букв с диакритическими знаками. Обычно эти флаги не используются, и dwFlags равен 0. Параметр pMultiByteStr указывает на преобразуемую строку, a cchMultiByte определяет ее длину в байтах Функция самостоятельно определяет длину строки, если cchMultiByte равен -1.
Unicode-версия строки, полученная в результате преобразования, записывается в буфер по адресу, указанному в pWideCharStr. Максимальный размер этого буфера (в символах) задается в параметре cchWideCbar. Если он равен 0, функция ничего не преобразует, а просто возвращает размер буфера, необходимого для сохранения результата преобразования. Обычно конверсия мультибайтовой строки в ее Unicode-эквивалент проходит так:
1. Вызывают MultiByteToWideChar, передавая NULL в параметре pWideCharStr и 0 в
параметре cchWideChar.
2. Выделяют блок памяти, достаточный для сохранения преобразованной стро-
ки. Его размер получают из предыдущего вызова MultiByteToWideChar.
3. Снова вызывают MultiByteToWideChar, на этот раз передавая адрес выделенно го буфера в параметре pWideCharStr, а размер буфера, полученный при первом обращении к этой функции, — в параметре cchWideChar.
4. Работают с полученной строкой.
5. Освобождают блок памяти, занятый Unicode-строкой.
Обратное преобразование выполняет функция WideCharToMultiByte
int WideCharToMultiByte(
UINT uCodePage,
DWORD dwFlags,
PCWSTR pWideCharStr,
int cchWideChar,
PSTR pMultiByteStr,
int cchMultiByte,
PCSTR pDefaultChar,
PBOOL pfUsedDefaultChar);
Она очень похожа на MultiByteToWideChar. И опять uCodePage определяет кодовую страницу для строки — результата преобразования Дополнительный контроль над процессом преобразования дает параметр dwFlags. Его флаги влияют на символы с диакритическими знаками и на символы, которые система не может преобразовать. Такой уровень контроля обычно не нужен, и dwFlags приравнивается 0
Пapaметр pWideCharStr указывает адрес преобразуемой строки, a cchWideChar задает ее длину в символах. Функция сама определяет длину исходной строки, если cchWideChar равен -1.
Мультибайтовый вариант строки, полученный в результате преобразования,
записывается в буфер, на который указывает pMultiByteStr, Параметр cchMultiByte
определяет максимальный размер этого буфера в байтах Передав нулевое значение в
ccbMultiByte, Вы заставите функцию сообщить размер буфера, требуемого для записи
результата. Обычно конверсия широкобайтовой строки в мультибайтовую проходит в
той
же последовательности, что и при обратном преобразовании
Очевидно, Вы заметили, что WideCharToMultiByte принимает на два параметра больше, чем MultiByteToWideCbar, это pDefauItChar pfUsedDefaultChar. Функция WideCharToMultiByte использует их, только если встречает широкий символ, не представленный в кодовой странице, на которую ссылается uCodePage Если его преобразование невозможно, функция берет символ, на который указывает pDefaultChar. Если этот параметр равен NULL (как обычно и бывает), функция использует системный символ по умолчанию. Таким символом обычно служит знак вопроса, что при операциях с именами файлов очень опасно, поскольку он является и символом подстановки.
Параметр pfUsedDefaultChar указывает на переменную типа BOOL, которую функция устанавливает как TRUE, если хоть один символ из широкосимвольной строки не преобразован в свой мультибайтовый эквивалент. Если же все символы преобразованы успешно, функция устанавливает переменную как FALSE. Обычно Вы передаете NULL в этом параметре.
Подробнее эти функции и их применение описаны в документации Platform SDK.
Эти две функции позволяют легко создавать ANSI- и Unicode-версии других функций, работающих со строками. Например, у Вас есть DLL, содержащая функцию, которая переставляет все символы строки в обратном порядке Unicode-версию этой функции можно было бы написать следующим образом.
BOOL StringReverseW(PWSTR pWidoCharStr) {
// получаем указатель на последний символ в строке
PWSTR pEndOfStr = pWideCharStr + wcslen(pWideCharStr) - 1;wchar_t cCharT;
// повторяем, пока не дойдем до середины строки
while (pWideCharStr < pEndOfStr) {
// записываем символ во временную переменную
cCharT = *pWideCharStr;// помещаем последний символ на место первого
*pWideCharStr = *pEndOfStr;// копируем символ из временной переменной на место последнего символа
*pEndOfStr = cCharT;// продвигаемся на 1 символ вправо
pWideCharStr++ж// продвигаемся на 1 символ влево
pEndOfStr--;
}// строка обращена; сообщаем об успешном завершении
return(TRUE);
}ANSI-версию этой функции можно написать так, чтобы она вообще ничем не занималась, а просто преобразовывала ANSI-строку в Unicode, передавала ее в функцию StringReverseW и конвертировала обращенную строку снова в ANSI. Тогда функция должна выглядеть примерно так:
BOOL StringReverseA(PSTR pMultiByteStr) {
PWSTR pWideCharStr;
int nLenOfWideCharStr;
BOOL fOk = FALSE;// вычисляем количество символов, необходимых
// для хранения широкосимвольной версии строки
nLenOfWideCharStr = MultiRyteToWideChar(CP_ACP, 0,
pMultiByteStr, -1, NULL, 0);// Выделяем память из стандартной кучи процесса,
// достаточную для хранения широкосимвольной строки,
// Не забудьте, что MultiByteToWideChar возвращает
// количество символов, а не байтов, поэтому мы должны
// умножить это число на размер широкого символа.
pWideCharStr = HeapAlloc(GetProcessHeap(), 0, nLenOfWideCharStr * sizeof(WCHAR));if (pWideCharStr == NULL)
return(fOk);
// преобразуем нультибайтовую строку в широкосимвольную
MultiByteToWideChar(CP_ACP, 0, pMulti8yteStr, -1, pWideCharStr, nLenOfWideCharStr);// вызываем широкосимвольную версию этой функции для выполнения настоящей работы
fOk = StnngReverseW(pWideCharStr);if (fOk} {
// преобразуем широкосимвольную строку обратно в мультибайтовую
WideCharToMultiByte(CP_ACP, 0, pWideCharStr, -1, pMultiByteStr, strlen(pMultiByteStr), NULL, NULL);
}// освобождаем память, выделенную под широкобайтовую строку
HeapFree(GetProcessHeap(), 0, pWideCharStr);return(fOk),
}
И, наконец, в
заголовочном файле, поставляемом вместе с DLL, прототипы этих функций были бы
такими:
BOOL StringReverseW (PWSTR pWideCharStr);
BOOL StringReverseA (PSTR pMultiByteStr);#ifdef UNICODE
#define StnngReverse StringReverseW
#else
#define StringRevcrsc StringReverseA
#endif // UNICODE
![]()
![]()
![]()