Новые книги
 СМИ сегодня – это мощное, сложное и эффективное оружие, которое нужно уметь применять. Каждый специалист по связям с общественностью должен не только создавать информационные поводы и писать об этом интересные материалы, но и заинтересовывать журналистов. Поэтому и существует на рынке знаний PR отдельная область – медиарилейшнз (MR), представляющая собой искусство взаимодействия бизнеса, политиков, государственных и общественных организаций, с одной стороны, и представителей СМИ – с другой. СМИ сегодня – это мощное, сложное и эффективное оружие, которое нужно уметь применять. Каждый специалист по связям с общественностью должен не только создавать информационные поводы и писать об этом интересные материалы, но и заинтересовывать журналистов. Поэтому и существует на рынке знаний PR отдельная область – медиарилейшнз (MR), представляющая собой искусство взаимодействия бизнеса, политиков, государственных и общественных организаций, с одной стороны, и представителей СМИ – с другой.Александр Назайкин – известный консультант по рекламе и медиарилейшнз, подробно описывает специфику работы СМИ и рассказывает, как на регулярной основе создавать информационные поводы, писать интересные материалы и доводить свои статьи и пресс-релизы до публикации. Книга рассчитана на действующих специалистов по медиарилейшнз, а также работников PR-индустрии. |

Глава 18. Динамически распределяемая память
ГЛАВА 18 Динамически распределяемая память
Третий, и последний, мехянизм управления памятью — динамически распределяемые области памяти, или кучи (heaps). Они весьма удобны при создании множества не больших блоков данных. Например, связанными списками и деревьями проще мани пулировать, используя именно кучи, а не виртуальную память (глава 15) или файлы, проецируемые в память (глава 17) Преимущество динамически распределяемой па мяти в том, что она позволяет Вам игнорировать гранулярность выделения памяти и размер страниц и сосредоточиться непосредственно на своей задаче. А недостаток — выделение и освобождение блоков памяти проходит мсдлсннсс, чсм при использова нии других механизмов, и, кроме того, Вы теряете прямой контроль над передачей физической памяти и ее возвратом системе.
Куча — это регион зарезервированного адресного пространства. Первоначально большей его части физическая память не передается. По мере того, как программа занимает эту область под данные, специальный диспетчер, управляющий кучами (heap manager), постранично передаст ей физическую память (из страничного файла). А при освобождении блоков в куче диспетчер возвращает системе соответствующие стра ницы физической памяти.
Microsoft не документирует правила, по которым диспетчер передает или отбира ет физическую память. Эти правила различны в Windows 98 и Windows 2000. Могу сказать Вам лишь следующее; Windows. 98 больше озабочена эффективностью исполь зования памяти и поэтому старается как можно быстрее отобрать у куч физическую память. Однако Windows 2000 нацелена главным образом на максимальное быстро действие, в связи с чем возвращает физическую память в страничный файл, только если страницы не используются в течение определенного времени. Microsoft посто янно проводит стрессовое тестирование своих операционных систем и прогоняет разные сценарии, чтобы определить, какие правила в большинстве случаев работают лучше. Их приходится менять по мере появления как нового программного обеспе чения, так и оборудования. Если эти правила важны Вашим программам, использо вать динамически распределяемую память пе стоит — работайте с функциями вирту альной памяти (т. e. VirtualAlloc и VirtualFree), и тогда Вы сможете сами контролиро вать эти правила.
Стандартная куча процесса
При инициализации процесса система создает в его адресном пространстве стандарт ную кучу (process's default heap) Ее размер по умолчанию — 1 Мб Но система позво ляет увеличивать этот размер, для чего надо указать компоновщику при сборке про
граммы ключ /HEAP (Однако при сборке DLL этим ключом пользоваться нельзя, так какдля DLL куча не создается.)
/HEAP:reserve[,commit]
Стандартная куча процесса необходима многим Windows-функциям. Например, функции ядра Windows 2000 выполняют все операции с использованием Unicode символов и строк Если вызвать ANSI-версию какой-нибудь Windows-функции, ей придется, преобразовав строки ил ANSI в Unicode, вызывать свою Unicode-версию. Для преобразования строк ANSI-функции нужно выделить блок памяти, в котором она размещает Unicode-версию строки. Этот блок памяти заимствуется из стандартной кучи вызывающего процесса. Есть и другие функции, использующие временные бло ки памяти, которые тоже выделяются из стандартной кучи процесса Из нее же чер пают себе память и функции 16~разрядной Windows, управляющие кучами (LocalAlloc и GlobalAlloc).
Поскольку стандартную кучу процесса используют многие Windows-функции, а потоки Вашего приложения могут одновременно вызвать массу таких функций, дос туп к этой куче разрешается только по очереди. Иными словами, система гарантиру ет, что в каждый момент времени только один поток сможет выделить или освобо дить блок памяти в этой куче. Если же два потока попытаются выделить в ней блоки памяти одновременно, второй поток будет ждать, пока первый поток не выделит свой блок. Принцин последовательного доступа потоков к кучс немного снижает произ водительность многопоточной программы. Если в программе всего один поток, для быстрейшего доступа к кучс нужно создать отдельную кучу и нс использовать стан дартную. Но Windows-функциям этого, увы, не прикажешь — они работают с кучей только последнего типа.
Как я уже говорил, куч у одного процесса может быть несколько. Они создаются и разрушаются в период его существования. Но стандартная куча процесса создается в начале его исполнения и автоматически уничтожается по его завершении — сами уничтожить ее Вы нс можете. Каждую кучу идентифицирует своЙ описатель, и все Windows-функции, которые выделяют и освобождают блоки в ее пределах, требуют передавать им этот описатель как параметр.
Описатель стандартной кучи процесса возвращает функция GеtProcessHeap.
HANDLE GelProcessHeap();
Дополнительные кучи в процессе
В адресном пространстве процесса допускается создание дополнительных куч. Для чего они нужны? Тому может быть несколько причин:
- защита компонентов;
- более эффективное управление памятью;
- локальный доступ;
- исключение издержек, связанных с синхронизацией потоков;
- быстрое освобождение всей памяти в куче.
Рассмотрим эти причины подробнее.
Защита компонентов
Допустим, программа должна обрабатывать два компонента- связанный список струк тур NODE и двоичное дсрсво структур BRANCH. Представим также, что у Вас есть два
файла исходного кода: LnkLst.cpp, содержащий функции для обработки связанного списка, и BinTree.cpp с функциями для обработки двоичного дерева
Если структуры NODE и BRANCH хранятся в одной куче, то она может выглядеть примерно так, как показано на рис. 18-1.
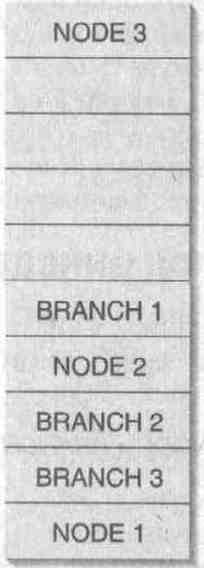
Рис. 18-1. Единая куча, в которой размещены структуры NODE и BRANCH
Теперь предположим, что в коде, обрабатывающем связанный список, «сидит жу чок", который приводит к случайной перезаписи 8 байтов после NODE 1 А это в свою очередь влечет порчу данных в BRANCH 3 Впоследствии, когда код из файла Bin Tree.cpp пьтается «пройти" по двоичному дереву, происходит сбой из-за того, что часть данных в памяти испорчена. Можно подумать, что ошибка возникает из-за «жуч ка» в коде двоичного дерева, тогда как на самом деле он — в коде связанного списка. А поскольку разные типы объектов смешаны в одну кучу (в прямом и переносном смысле), то отловить «жучков» в коде становится гораздо труднее.
Создав же две отдельные кучи — одну для NODE, другую для BRANCH, — Вы ло кализуете место возникновения ошибки. И тогда «жучок» в коде связанного списка не испортит целостности двоичного дерева, и наоборот. Конечно, всегда остается веро ятность такой фатальной ошибки в коде, которая приведет к записи данных в посто роннюю кучу, но это случается значительно реже.
Более эффективное управление памятью
Кучами можно управлять гораздо эффективнее, создавая в них объекты одинакового размера. Допустим, каждая структура NODE занимает 24 байта, а каждая структура BRANCH — 32. Памятьдля всех этих объектов выделяется из одной кучи. На рис. 18-2 показано, как выглядит полностью занятая куча с несколькими объектами NODE и BRANCH. Если объекты NODE 2 и NODE 4 удаляются, память в куче становится фраг ментированной И если после этого попытаться выделить в ней память для структу ры BRANCH, ничего не выйдет — даже несмотря на то что в куче свободно 48 байтов, а структура BRANCH требует всего 32.
Если бы в каждой куче содержались объекты одинакового размера, удаление од ного из них позволило бы в дальнейшем разместить другой объект того же типа.
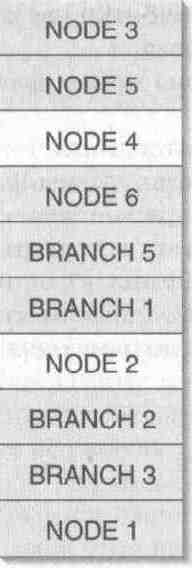
Рис. 18-2. Фрагментированная куча, содержащая несколько объектов NODE и BRANCH
Локальный доступ
Перекачка страницы ил оперативной памяти в страничный файл занимает ощутимое время. Та же задержка происходит и в момент загрузки страницы данных обратно в оперативную память. Обращаясь в основном к памяти, локализованной в небольшом диапазоне адресов, Вы снизите вероятность перекачки страниц между оперативной памятью и страничным файлом.
Поэтому при разработке приложения старайтесь размещать объекты, к которым необходим частый доступ, как можно плотнее друг к другу. Возвращаясь к примеру со связанным списком и двоичным деревом, отмечу, что просмотр списка не связан с просмотром двоичного дерева Разместив все структуры NODE друг за другом в од ной куче, Вы, возможно добьетесь того, что по крайней мере несколько структур NODE умесгятся в пределах одной страницы физической памяти. И тогда просмотр связанного списка не потребует от процессора при каждом обращении к какой-либо структуре NODE переключаться с одной страницы на другую.
Если же «свалить" оба типа cтpyктyp в одну кучу, обьекты NODE необязательно будут размещены строго друг за другом. При самом неблагоприятном стечении об стоятельств на странице окажется всего одна структура NODE, a остальное место зай мут структуры BRANCH. B этом случае просмотр связанного списка будет приводить к ошибке страницы (page fault) при обращении к каждой структуре NODE, что в ре зультате может чрезвычайно замедлить скорость выполнения Вашего процесса.
Исключение издержек, связанных с синхронизацией потоков
Доступ к кучам упорядочивается по умолчанию, поэтому при одновременном обра щении нескольких потоков к куче данные в ней никогда не повреждаются. Однако для этого функциям, работающим с кучами, приходится выполнять дополнительный код. Если Вы интенсивно манипулируете с динамически распределяемой памятью, выпол нение дополнительного кода может заметно снизить быстродействие Вашей програм мы. Создавая новую кучу, Вы можете сообщить системе, что единовременно к этой кучс обращается только один поток, и тогда дополнительный код выполняться не
будет. Но береритесь: теперь Вы берете всю ответственность за целостность этой кучи на себя. Система не станет присматривать за Вами.
Быстрое освобождение всей памяти в куче
Наконец, использование отдельной кучи для какой-то структуры данных позволяет освобождать всю кучу, не перебирая каждый блок памяти. Например, когда Windows Explorer перечисляет иерархию каталогов на жестком диске, он формирует их дере во в памяти. Получив команду обновить эту информацию, он мог бы просто разру шить кучу, содержащую это дерево, и начать все заново (если бы, конечно, он исполь зовал кучу, выделенную только для информации о дереве каталогов). Бо многих при ложениях это было бы очень удобпо, да и быстродействие тоже возросло бы.
Создание дополнительной кучи
Дополнительные кучи в процессе создаются вызовом HeapCreate
HANDLE HeapCreate( DWORD fdwOptions, SIZE_T dwInitialSize, SIZE_T dwMaximumSize);
Параметр fdwOptions модифицирует способ выполнения операций над кучей. В нем можно указать 0, HEAP_NO_SERIALIZE, HEAP_GENERATE_EXCEPTIONS или комбинацию последних двух флагов.
По умолчанию действует принцип последовательного доступа к куче, что позво ляет не опасаться одновременного обращения к ней сразу нескольких потоков. При попытке выделения из кучи блока памяти функция HeapAlloc (ее параметры мы обсу дим чуть позже) делает следующее:
- Просматривает связанный список выделенных и свободных блоков памяти.
- Находит адрес свободного блока.
- Выделяет новый блок, помечая свободный как занятый.
- Добавляет новый элемент в связанный список блоков памяти.
Флаг HEAP_NO_SERIALIZE использовать нс следует, и вот почему. Допустим, два потока одновременно пытаются выделить блоки памяти из одной кучи. Первый по ток выполняет операции по пп 1 и 2 и получает адрес свободного блокз памяти. Но только он соберется перейти к третьему этапу, как сго вытеснит второй поток и тоже выполнит операции по пп. 1 и 2. Поскольку первый поток не успел дойти до этапа 3, второй поток обнаружит тот же свободный блок памяти,
Итак, оба потока считают, что они нашли свободный блок памяти в куче. Поэтому поток 1 обновляет связанный список, помечая новый блок как занятый. После этого и поток 2 обновляет связанный список, помечая тот же блок как занятый. Ни один из потоков пока ничего не подозревает, хотя оба получили адреса, указывающие на один и тот же блок памяти.
Ошибку такого рода обнаружить очень трудно, поскольку она проявляется не сра зу. Но в конце концов сбой произойдет и, будьте уверены, это случится в самый не подходящий момент, Вот какие проблемы это может вызвать.
- Повреждение связанного списка блоков памяти. Эта проблема не проявится до попытки выделения или освобождения блока.
- Оба потока делят один и тот же блок памяти. Оба записывают в него свою информацию Когда поток 1 начнет просматривать содержимое блока, он не поймет данные, записанные потоком 2.
- Один из потоков, закончив работу с блоком, освобождает его, и это приводит к тому, что другой поток записывает данные в невыделенную память Проис ходит повреждение кучи.
Решение этих проблем — предоставить одному из потоков монопольный доступ к куче и ее связанному списку (пока он не закончит все необходимые операции с кучей) Именно так и происходит в отсутствие флага HEAP_NO_SERIALIZE Этот флаг можно использовать без опаски только при выполнении следующих условий'
- в процессе существует лишь один поток;
- в процессе несколько потоков, но с кучей работает лишь один из них;
- в процессе несколько потоков, но он сам регулирует доступ потоков к кучс, применяя различные формы взаимоисключения, например критические сек ции, объекты-мьютексы или семафоры (см. главы 8 и 9).
Если Вы не уверены, нужен ли Вам флаг HEAP_NO_SERIALIZE, лучше не пользуй тесь им. В его отсутствие скорость работы многопоточной программы может чуть снизиться из-за задержек при вызовах функций, управляющих кучами, но зато Вы избежите риска повреждения кучи и ее данных.
Другой флаг, HEAP_GENERATE_EXCEPTIONS, заставляет систему генерировать ис ключение при любом провале попытки выделения блока в куче Исключение (см. гла вы 23, 24 и 25) — еще один способ уведомления программы об ошибке. Иногда при ложение удобнее разрабатывать, полагаясь на перехват исключений, а не на провер ку значений, возвращаемых функциями.
Второй параметр функции HeapCreate — dwlnilialSize — определяет количество байтов, первоначально передаваемых куче. При необходимости функция округляет это значение до ближайшей большей величины, кратной размеру страниц И после дний параметр, clwMaximumSize, указывает максимальный объем, до которого может расширяться куча (предельный объем адресного пространства, резервируемого под кучу). Если он больше 0, Вы создадите кучу именно такого размера и не сможете его увеличить. А если этот параметр равен 0, система резервирует регион и, если надо, расширяет его до максимально возможного объема При успешном создании кучи HeapCreate возвращает описатель, идентифицирующий новую кучу Он используется и другими функциями, работающими с кучами.
Выделение блока памяти из кучи
Для этого достаточно вызвать функцию HeapAlloc
PVOID HeapAlloc( HANDLE hHeap, DWORD fdwFlags, SIZE_T dwBytes);
Параметр hHeap идентифицирует описатель кучи, из которой выделяется память. Параметр dwBytes определяет число выделяемых в куче байтов, а параметр fdwFlags позволяет указывать флаги, влияющие на характер выделения памяти В настоящее время поддерживается только три флага. HEAP_ZERO_MEMORY, HEAP_GENERATE_EX CEPTIONS и HEAP_NO_SERIALIZE.
Назначение флага HEAP_ZERO_MEMORY очевидно Он приводит к заполнению содержимого блока нулями перед вовратом из HeapAlloc. Второй флаг заставляет эту функцию генерировать программное исключение, если в куче не хватает памяти для удовлетворения запроса. Вспомните, этот флаг можно указывать и при создании кучи функцией HeapCreate, он сообщает диспетчеру, управляющему кучами, что при невоз можности выделения блока в куче надо генерировать соответствующее исключение. Если Вы включили данный флаг при вызове HeapCreate, то при вызове HeapAlloc ука зывать его ужс не нужно С другой стороны, Вы могли создать кучу без флага HEAP_GE NERATE_EXCEPTIONS. В таком случае, если Вы укажете его при вызове HeapAlloc, он повлияет лишь на данный ее вызов.
Если функция HeapAlloc завершилась неудачно и при этом разрешено генериро вать исключения, она может вызвать одно из двух исключений, перечисленных в сле дующей таблице
|
Идентификатор |
Описание |
|
STATUS_NO_MEMORY |
Попытка выделения памяти не удалась из-за ее нехватки |
|
STATUS_ACCESS_VIOLATION |
Попытка выделения памяти не удалась из-зa повреждения кучи или неверных параметров функции |
При успешном выделении блока HeapAlloc возвращает егo адрес Если памяти не достаточно и флаг HEAP_GENERATE_EXCEPTIONS не указан, функция возвращает NULL.
Флаг HEAP_NO_SERIALIZE заставляет HeapAlloc при данном вызове нс применять принцип последовательного доступа к куче Этим флагом нужно пользоваться с ве личайшей осторожностью, так как куча (особенно стандартная куча процесса) может быть повреждена при одновременном доступе к ней нескольких потоков
WINDOWS 98
Вызов HeapAlloc с требованием выделить блок размером более 256 Мб Win dows 98 считает ошибкой. Заметьте, что в этом случае функция всегда возвра щает NULL, a исключение никогда не генерируется, даже если при создании кучи или попытке выделить блок Вы указали флаг HEAP_GENERATE_EXCEPTIONS,NOTE:
Для выделения больших блоков памяти (от 1 Мб) рекомендуется использовать функцию VirtualAlloc, а не функции, оперирующие с кучами.
Изменение размера блока
Часто бывает необходимо изменить размер блока памяти. Некоторые приложения изначально выделяют больший, чем нужно, блок, а затем, разместив в нем данные, уменьшают его Но некоторые, наоборот, сначала выделяют небольшой блок памяти и потом увеличивают его по мере записи новых данных. Для изменения размера бло ка памяти вызывается функция HeapReAlloc:
PVOID HeapReAlloc( HANDLE hHeap, DWORD fdwFlags, PVOID pvMem, SIZE_Т dwBytes);
Как всегда, параметр hHeap идентифицирует кучу, в которой содержится изменя емый блок. Параметр fdwFlags указывает флаги, используемые при изменении разме
pa блока HEAP_GENERATE_EXCEPTIONS, HEAP_NO_SERIALIZE, HEAP_ZEROMEMORY или HEAP_REALLOC_IN_PLACE_ONLY.
Первые два флага имеют тот же смысл, что и при использовании с HeapAlloc. Флаг HEAPZEROMEMORY полезен только при увеличении размера блока памяти. В этом случае дополнительные байты, включаемые в блок, предварительно обнуляются. При уменьшении размера блока этот флаг не действует.
Флаг HEAP_REALLOC_IN_PLACE_ONLY сообщает HeapReAlloc, что данный блок памяти перемещать внутри кучи не разрешается (а именно это и может попытаться сделать функция при расширении блока). Если функция сможет расширить блок без его перемещения, она расширит его и вернет исходный адрес блока. С другой сторо ны, ссли для расширения блока его надо переместить, оня возвращает адрес нового, большего по размеру блока. Если блок затем снова уменьшается, функция вновь воз вращает исходный адрес первоначального блока. Флаг HEAP_REALLOC_IN_PLACE_ ONLY имеет смысл указывать, когдя блок является частью связанного списка или де рева. В этом случае в других узлах списка или дерева могут содержаться указатели на данный узел, и его перемещение в куче непременно приведет к нарушению целост ности связанного списка
Остальные два параметра (pvMem и dwBytes) определяют текущий адрес изменяе мого блока и сго новый размер (в байтах). Функция HeapReAlloc возвращает либо ад рес нового, измененного блока, либо NULL, ссли размер блока изменить не удалось.
Определение размера блока
Выделив блок памяти, можно вызвать HeapSize и узнать сго истинный размер
SIZE_T HeapSize( HANDLE hHeap, DWORD fdwFlags, LPCVOlD pvMem);
Параметр hHeap идентифицирует кучу, а параметр pvMem сообщает адрес блока. Параметр dfwFlags принимает два значения: 0 или HEAP_NO_SERIALIZE
Освобождение блока
Для этого служит функция HeapFree.
BOOL HeapFree( HANDLE hHeap, DWORD fdwFlags, PVOID pvMem);
Она освобождает блок памяти и при успешном вызове возвращает TRUE. Параметр fdwFlags принимает два значения 0 или HEAP_NO_SFRIALIZE Обращение к этой фун кции может привести к тому, что диспетчер, управляющий кучами, вернет часть фи зической памяти системе, но это не обязательно.
Уничтожение кучи
Кучу можно уничтожить вызовом HeapDestroy-.
BOOL HeapDestroy(HANDLE hHeap);
Обращение к этой функции приводит к освобождению всех блоков памяти внут ри кучи и возврату системе физической памяти и зарезервированного региона адрес
ного пространства, занятых кучей При успешном выполнении функция возвращает TRUE. Если при завершении процесса Вы не уничтожаете кучу, это делает система, но — подчеркну еще раз — только в момент завершения процесса. Если куча создана потоком, она будет уничтожена лишь при завершении всего процесса
Система не позволит уничтожить стандартную кучу процесса — она разрушается только при завершении процесса. Если Вы передадите описатель этой кучи функции HeapDestroy, система просто проигнорирует Ваш вызов.
Использование куч в программах на С++
Чтобы в поЛной мере использовать преимущества динамически распределяемой па мяти, следует включить ее поддержку в существующие программы, написанные па С++. В этом языке выделение памяти для объекта класса выполняется вызовом оператора new, а не функцией malloc, как в обычной библиотеке С. Когда необходимость в дан ном объекте класса отпадает, вместо библиотечной С-функции frее следует применять оператор delete. Скажем, у нас есть класс CSomeClasb, и мы хотим создать экземпляр этого класса. Для этого нужно написать что-то вроде.
CSomeClass* pSorneClass = new CSomeClass;
Дойдя до этой строки, компиляюр С++ сначала проверит, содержит ли класс CSomeClass функцию-член, переопределяющую оператор new. Если да, компилятор генерирует код для вызова этой функции Нет — создает код для вызова стандартно го С++-оператора new.
Созданный объект уничтожается обращением к оператору delete
delete pSomeClass;
Переопределяя операторы new и delete для нашегоC++ - класса, мы получаем воз можность использовать преимущества функций, управляющих кучами. Для этого оп ределим класс CSomeClass в заголовочном файле, скажем, так:
class CSomeClass
{private
static HANDLE s_hHeap;
static UINT s_uNumAllocsInHeap;// здесь располагаются закрытые данные и функции-члены
public:
void* operator new (size_t size);
void operator delete (void* p);// здесь располагаются открытые данные и функции-члены
...
};
Я объявил два элемента данных, s_hHeap и s_uNumAllocs!nHeap, как статические переменные А раз так, то компилятор С++ заставит все экземпляры класса CSomeClass использовать одни и те же переменные. Иначе говоря, он не станет выделять отдель ные переменные s_hHeap и s_uNumAllocsInHeap для каждого создаваемого экземпля ра класса. Это очень важно: ведь мы хотим, чтобы все экземпляры класса CSomeClass были созданы в одной куче.
Переменная s_hHeap будет содержать описатель кучи, в которой создаются объек ты CSomeClass. Переменная s_uNumAllocsInHeap — просто счетчик созданных в куче
объектов CSomeClass. Она увеличивается на 1 при создании в куче нового объекта CSomeClass и соответственно уменьшается при его уничтожении. Когда счетчик об нуляется, куча освобождается. Для управления кучей в СРР-файл следует включить примерно такой код:
HANDLE CSomeClass::s_hHeap = NULL;
UINT CSomeClass::s_uNumAllocsInHeap = 0;void* CSomnClass::operator new (size_t size)
{if (s_hHeap == NULL)
{// куча не существует, создаем ее
s_hHeap = HeapCreate(HEAP_NO_SERIALIZE, 0, 0);if (s_hHeap == NULL)
return(NULL);
}
// куча для объектов CSomeClass существует
void* p = HeapAlloc(s hHeap, 0, size);if (p != NULL)
{// память выделена успешно; увеличиваем счетчик объектов CSomeClass в куче
s_uNumAllocsInHeap++;
}
// возвращаем адрес созданного объекта CSomeClass
return(p);}
Заметьте, что сначала я объявил два статических элемента данных, s_hHeap и s_uNumAllocsInHeap, а затем инициализировал их значениями NULL и 0 соответственно.
Оператор new принимает один параметр — size, указывающий число байтов, нуж ных для хранения CSomeClass Первым делом он создает кучу, если таковой нет Для проверки анализируется значение переменной s_bHeap: если оно NULL, кучи нет, и тогда она создается функцией HeapCreate, а описатель, возвращаемый функцией, со храняется в переменной s_bHeap, чтобы при следующем вызове оператора new ис пользовать существующую кучу, а не создавать еще одну.
Вызывая HeapCreate, я указал флаг HEAP_NO_SERIALIZE, потому что данная про грамма построена как однопоточная. Остальные параметры, указанные при вызове HeapCreate, определяют начальный и максимальный размер кучи. Я подставил на их место по нулю. Первый нуль означает, что у кучи нет начального размера, второй — что куча должна расширяться по мере необходимости.
Hе исключено, что Вам показалось, будто параметр size оператора new стоит пе редать в HeapCreatc как второй параметр. Вроде бы тогда можно инициализировать кучу так, чтобы она была достаточно большой для размещения одного экземпляра класса. И в таком случае функция HeapAlloc при первом вызове работала бы быстрее, так как не пришлось бы изменять размер кучи под экземпляр класса. Увы, мир устро ен не так, как хотелось бы. Из-за того, что с каждым выделенным внутри кучи блоком памяти связан свой заголовок, при вызове HeapAlloc все равно пришлось бы менять размер кучи, чтобы в нее поместился не только экземпляр класса, но и связанный с ним загловок.
После создания кучи из нее можно выделять память под новые объекты CSomeClass с помощью функции HeapAlloc. Первый параметр — описатель кучи, второй — раз мер объекта CSomeClass. Функция возвращает адрес выделенного блока.
Если выделение прошло успешно, я увеличиваю переменную-счетчик s_uNum AllocsInHeap, чтобы знать число выделенных блоков в куче. Наконец, оператор new возвращает адрес только что созданного объекта CSomeClass.
Вот так происходит создание нового объекта CSomeClasb. Теперь рассмотрим, как этот объект разрушается, — если он больше не нужен программе. Эта задача возлага ется на функцию, переопределяющую оператор delete.
void CSomeClass::operator delete (void* p)
{if (HeapFrce(s_hHcap, 0, p))
{// объект удален успешно
s_uNumAllocsInKeap--;}
if (s_uNumAllocsInHeap == 0)
{// если в куче больше нет объектов, уничтожаем ее
if (HeapDestroy(s_hHeap))
{// описатель кучи приравниваем NULL, чтобы оператор new
// мог создать новую кучу при создании нового объекта
CSomeClass s_hHeap = NULL;}
}
}
Оператор delete принимает только один параметр: адрес удаляемого объекта. Сна чала он вызывает HeapFree и передает ей описатель кучи и адрес высвобождаемого объекта. Если объект освобожден успешно, s_uNumAllocslnHeap уменьшается, показы вая, что одним объектом CSomeClass в куче стало меньше. Далее оператор проверяет: не равна ли эта переменная 0, и, если да, вызывает HeapDestroy, передавая ей описа тель кучи. Если куча уничтожена, s_hHeap присваивается NULL. Это важно: ведь в бу дущем наша программа может попытаться создать другой объект CSomeClass. При этом будет вызван оператор new, который проверит значение s_hHeap, чтобы опре делить, нужно ли использовать существующую кучу или создать новую.
Данный пример иллюстрируеn очень удобную схему работы с несколькими куча ми. Этот код легко подстроить и включить в Ваши классы. Но сначала, может быть, стоит поразмыслить над проблемой наследования. Если при создании нового класса Вы используете класс CSomeClass как базовый, то производный класс унаследует опе раторы new и delete, принадлежащие классу CSomeClass. Новый класс унаследует и его кучу, а это значит, что применение оператора new к производному классу повлечет выделение памяти для объекта этого класса из той же кучи, которую использует и класс CSomeClass. Хорошо это или нет, зависит от конкретной ситуации. Если объек ты сильно различаются размерами, это может привести к фрагментации кучи, что зятруднит выявление таких ошибок в коде, о которых я рассказывал в разделах «За щита компонентов» и «Более эффективное управление памятью».
Если Вы хотите использовать отдельную кучу для производных классов, нужно продублировать все, что я сделал для класса CSomeClass. Л конкретнее - включить еще один набор переменных s_hHeap и s_uNumAllocsInHeap и повторить еще раз код для операторов new и delete. Компилятор увидит, что Вы переопределили в производном классе операторы new и delete, и сформирует обращение именно к ним, а не к тем, которые содержатся в базовом классе.
Если Вы не будете создавать отдельные кучи для каждого класса, то получите един ственное преимущество: Вам не придется выделять память под каждую кучу и соот ветствующие заголовки. Но кучи и заголовки не занимают значительных объемов
памяти, так что даже это преимущество весьма сомнительно Неплохо, конечно, если каждый класс, используя свою кучу, в то же время имеет доступ к куче базового клас са. Но делать так стоит лишь после полной отладки приложения. И, кстати, проблему фрагментации куч это не снимает.
Другие функции управления кучами
Кроме уже упомянутых, в Windows есть еще несколько функций, предназначенных для управления кучами. В этом рязделс я вкратце расскажу Вам о них.
ToolHelp-функции (упомянутые в конце главы 4) дают возможность перечислять кучи процесса, а также выделенные внутри них блоки памяти. За более подробной информацией я отсылаю Вас к документации Plarform SDK: ищите разделы по функ циям Heap32Ftrst, Heap32Next, Heap32ListFirst и Heap32ListNext. Самое ценное в этих функциях то, что они доступны как в Windows 98, так и в Windows 2000. Прочие функ ции, о которых пойдет речь в этом разделе, есть только в Windows 2000.
В адресном пространстве процесса может быть несколько куч, и функция GetPro cessHeaps позволяет получить их описатели "одним махом":
DWORD GetProcessHeaps( DWORD dwNumHeaps, PHANDLE pHeaps);
Предварительно Вы должны создать массив описателей, а затем вызвать функцию так, как показано ниже.
HANDLE hHeaps[25];
DWORD dwHeaps = GetProcessHeaps(25, hHeaps);
if (dwHeaps > 25)
{// у процесса больше куч, чем мы ожидали
}
else
{// элеметы от hHeaps[0] до hHeaps[dwHeaps - 1]
// идентифицируют существующие кучи}
Имейте в виду, что описатель стандартной кучи процесса тоже включается в этот массив описателей, возвращаемый функцией GetProcessHeaps. Целостность кучи позволяет проверить функция HeapValidate:
BOOL HeapValidate( HANDLE hHeap, DWORD fdwFlags, LPCVOID pvMem);
Обычно ее вызывают, передавая в hHeap описатель кучи, в dwFlags — 0 (этот па раметр допускает еще флаг HEAP_NO_SERIALIZE), а в pvMem — NULL. Функция про сматривает все блоки в куче, чтобы убедиться в отсутствии поврежденных блоков. Чтобы она работала быстрее, в параметре pvMem можно передать адрес конкретного блока, Тогда функция проверит только этот блок.
Для объединения свободных блоков в куче, а также для возврата системе любых страниц памяти, на которых нет выделенных блоков, предназначена функция Heap Compact:
UINT HeapCompact( HANDLE hHeap, DWORD fdwFlags);
Обычно в параметре fdwFlags передают 0, но можно передать и HEAP_NO_SE RIALIZE
Следующие две функции — HeapLock и HeapUnlock — используются парно
BOOL Hpaplock(HANDLE hHeap);
BOOL HeapUnlock(HANDLE hHeap);
Они предназначены для синхронизации потоков После успешного вызова Heap Lock поток, который вьзывал эту функцию становится владельцем указанной кучи Ьсли другой поток обращается к этой куче, указывая тот же описатель кучи, система приостанавливает его выполнение до тех пор, пока куча не будет разблокирована вызовом HeapUnlock
Функции HeapAlloc, HeapSize, HeapFree и другие — все обращаются к HeapLock и HeapUnlock, чтобы обеспечить последовательный доступ к куче Самостоятельно вы зывать эти функции Вам вряд ли понадобится
Последняя функция, предназначенная для работы с кучами, — HeapWalk
BOOL HeapWalk( HANDLE hHeap, PPROCESS_HEAP_ENTRY pHoapEntry);
Она предназначена только для отладки и позволяет просматривать содержимое кучи Обычно ее вызывают по несколько paз, передавая адрес структуры PROCESS_ HEAP_ENTRY (Вы должны сами создать ее экземпляр и инициализировать)
typedef struct _PROCESS_HEAP_ENTRY
{PVOID lpData;
DWORD cbData;
BYlE cbOverhead;
BYTE iRegionIndex;
WORD wFlags;union
{struct
{HANDLE hMem; DWORD dwReserved[ 3 ];
} Block;
struct
{DWORD dwCornmittedSize;
DWORD dwUnCommittedSize;
LPVOID lpFirstBlock;
LPVOID lpLastBlock;} Region;
};
} PROCESS_HEAP_ENTRY, *LPPROCESS_HEAP_ENTRY, *PPROCESS_HEAP_ENTRY;
Прежде чем перечислять блоки в куче, присвойте NULL элементу lpData, и это заставит функцию HeapWalk инициализировать все элементы структуры Чтобы пе рейти к следующему блоку, вызовите HeapWalk еще раз, переддв сй тот же описатель кучи и адрес той же структуры PROCESS_HFAPENTRY Если HeapWalk вернет FALSE, значит, блоков в куче больше нет Подробное описание элементов структуры PRO CESS_HEAP_ENTRY см. в документации PlatformSDK
Обычно вызовы функции HeapWalk "обрамляют" вызовами HeapLock и HeapUnlock, чтобы посторонние потоки не портили картину, создавая или удаляя блоки в просматриваемой куче
![]()
![]()
![]()