Движок для сайта своими руками |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
Движок для сайта своими руками. Вариант первый: если у вас нету базы...Каждый сайтостроитель в один прекрасный момент вдруг замечает, что он уже занимается не столько подготовкой новых метериалов для своего сайта, сколько банальными и рутинными вещами: там выковырял меню, заменил; там пересохранил, обновил; тут — copy, там — paste, а потом всё это save и upload. «Ну нет — думает вебмастер — так больше нельзя! Но что же делать?». А делать нужно движок для сайта... Эта статья — первая из задуманного мной цикла статей, в котором мы с вами попробуем сделать что-то наподобии движка для несложных сайтов. Мы рассмотрим также принципы отделения контента сайта от его оформления (дизайна) и способы автоматизации вебмастерского труда. Движком принято называть набор скриптов и программ, на основе которых держится, живёт и обновляется сайт. Движок может быть как простым PHP-скриптом и статьями, хранящимися в текстовых файлах определённого формата, так и сложным комплексом программных средств в связке с базами данных (MySQL, Oracle, etc.) и веб-службами, написанными на Java. Лучшим (но при этом не самым сложным) был бы вариант с применением баз данных. Но чаще всего вебмастерам база данных недоступна, поскольку дают её (насколько мне известно) только на платных хостингах. Поэтому наш первый движок мы организуем при помощи PHP и набора файлов. При этом можно себя утешить тем, что на работоспособность нашего сайта не будут влиять дополнительные факторы риска, вносящиеся использованием баз данных (все, я полагаю, уже слышали о истории с дырой в Microsoft SQL Server 2000) (1). Наш движок будет специалиально приспособленным под контент-проекты (то есть сайты, которые регулярно пополняются авторскими статьями или другими материалами). А это значит, что нам придётся сделать всё для удобного и быстрого обновления содержания сайта. Итак, для начала нам надо опредилить пару функций для чтения данных из файла. Перед тем, как приводить исходные коды, рассмотрим имеющиеся у нас (вернее, в PHP) средства для работы с файлами (а те, кто не в курсе — сразу и узнают). Функции чтения файлов в PHP.Вобщем, прочитать файл мы можем несколькими способами. Первый, и самый простой — это использовать функцию file(). Она, получив имя файла, сразу же возвращает массив строк этого самого файла:
Сделаем такую себе самопальную базу данных. Для неё нам, во-первых, понадобятся такие функции: одна для чтения контента страницы (например, текста статьи) из внешнего файла — загрузка данных; функция для загрузки шаблона из файла — то есть, загрузка оформления (дизайна).
Где-то здесь надо было бы прикрутить гранитную плиту с надписью «Регулярным выражениям от благодарных фанатов», поскольку без этой удобной штуки было бы очень сложно создать вышеприведённые функции. Рассмотрим немного подробнее, как эти выражения устроены. Писать много раз об одном и том же нет смысла, поэтому я процитирую одну из статей о регулярных выражениях (Источник: http://sitemaker.ru/): Регулярные выражения.Немного истории.Математик Стивен Клин впервые представил регулярные выражения в 1956, в результате его работы с рекурсивными наборами в естественном языке. Они были созданы как синтаксические наборы, использовавшиеся для нахождения соотвествий шаблонов в строках, которые позже помогали обращаться к появляющейся технологической информации, облегчая автоматизацию. С тех пор, регулярные выражения прошли через множество итераций, и текущий стандарт сохраняется ISO (Международной организацией по стандартизации) и определен Open Group, совместным усилием различных технических некоммерческих организаций (2). Соответствие символов.Трудность регулярных выражений состоит в том, что Вы хотите искать или чему это должно соответствовать. Без этой концепции, RE бесполезны. Каждое выражение будет содержать некоторую команду о том, что искать:
Операторы повторения.Операторы повторения, или квантификаторы, описывают сколько раз нужно искать указанную строку. Они используются вместе с соответствующим символу синтаксисом, чтобы искать многократные вхождения символов. В различных приложениях их поддержка может изменяться или быть неполной, поэтому нужно прочитать документацию к приложению, если вдруг шаблон не работает как ожидалось.
Якоря. Якоря описывают где соответствовать шаблону. Они могут быть удобными, когда Вы ищете общие строковые комбинации.
(конец цитаты, источник описания: http://sitemaker.ru/) Итак, продолжим. Созданные нами функции пригодятся для чтения статей из файлов и вывода списка самых новых статей. Причем для модификации всего этого нам нужно будет лишь написать новую статью в виде файла с определённым синтаксисом (см. ниже) и добавить её в папку на сервере.
Символы ¤{ и }¤ используется для отделения частей друг от друга. Имя части же никакого значения не имеет и может быть любым набором символов английского алфавита, пробела, подчеркивания или дефиса. Для вывода списка статей используется цикл, перебирающий все файлы из нужного каталога. Если он натыкается на файл *.art, то сразу на радостях добавляет его в масив. В зависимости от указанного параметра, он может либо добавить имя этого файла, либо название содержащейся в нём статьи, либо сразу готовую ссылку на эту статью. Что ж, небольшая часть работы над нашим движком уже проделана. Эта часть кода — основа нашего первого движка. Для конкретных целей к нему нужно цеплять дополнительные функции и создавать сами тексты и шаблоны страниц. Движок для сайта своими руками. Часть вторая.В прошлый раз мы рассмотрели способ организации «базы данных» без собственно самой базы данных. Сегодня продолжим тему создания «без-MySQL’ного» сайтового движка разговором об каталогах, файлах и include’ах. Также будет немного теории и практики о собственно работе такого двигателя.Основные принципы организации работы.Несложно догадаться, что организация устройства движка зависит от многих факторов, изменяющихся в каждом конкретном примере сайта. Это и предполагаемая структура информации, и особенности хостинга, на котором размещён сайт (наличие-отстутствие таких средств как PHP, SSI, доступность каких-либо баз данных, и т. п.), и не в меньшей степени при разработке устройства будущего движка нужно учитывать дизайн сайта, то есть структуру самих страниц. Собственно, одной из целей создания движка для сайта есть как раз организация удобной работы по обновлению материалов, и, как предусловие, практически полное отделение дизайна сайта от собственно его полезного содержания (во загнул ). Но в любом случае, будущий дизайн надо учитивать, каким образом — об этом немного позже. Итак, само слово «разделение» подразумевает уже, как минимум, разделение страницы сайта на два файла — с шаблоном дизайна (который может быть общим для нескольких страниц) и файла с самим контентом, то есть информацией. Кроме этих двух файлов нам понадобиться ещё один, включаемый во все динамические страницы (имеются ввиду страницы, содержащие PHP-код). В этом файле мы будем хранить все общие функции движка (собственно, их можно назвать «ядром»), а также определим некоторые полезные глобальные константы. Основной задачей функций ядра будет чтение файлов с текстами статей, картинками или иными материлами сайта, а также вывод этого контента в нужной форме на экран. Третью функцию — ввод данных — мы не рассматриваем, так как способ хранения данных (файлы с разделителями) позволяет вводить информацию при помощи стандартных средств (любимого текстового редактора, например). Таким образом, схема создания новых материалов сайта выглядит следующим образом:
Рис. 1. Текст → движок → страница сайта А под фразой «учитывать дизайн», высказанной немного выше, имелось ввиду создание системы шаблонов, или, проще говоря, набора оформлений разных страниц (HTML-файлов, по сути), где места под изменяемое содержание (заголовки, меню, тексты — всё, что генерируется динамически) оставлены пустыми. Подставлятся они будут «на лету» при обращении пользователя к определенной странице. Получается даже дополнительный выигрыш — кроме всего прочего, уменьшаеться объём хранимых на сервере файлов, так как оформление страниц не повторяется в каждом файле, а хранится в одном месте. Про удобство при возможном желании изменения дизайна, я думаю, и говорить не надо. Расположение файлов.Итак, вернемся к собственно организации нашей системы. Основной принцип, который будет использоваться в нашем примере — это одноуровневость разделов. Но не волнуйтесь — это лишь для упрощения примеров. Если для вас это слишком серъёзное ограничение — просто придется подождать следующего выпуска, в котором мы поищем обходные пути. Для работы нашего движка нужно организовать структуру каталогов таким образом, как на рис. 2 (этот пример просто используется в описанных примерах, структура не обязательно должна быть именно такой).
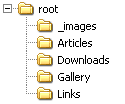
Рис. 2. Структура каталогов Итак, у нас имеются каталоги, каждый из которых является разделом сайта (естественно, кроме служебных каталогов, таких, как “images”). Это значит, что в каждом таком каталоге должен лежать так называемый «индексный файл» — страница, которая загружается по умолчанию при таком обращении к разделу: http://site.com/Razdel. Имя этого файла (или возможные имена) вам нужно узнать у вашего хостера. Чаще всего это такие имена, как “index.html”, “index.php” и т. п. — расширение зависит от используемого серверного языка. Значит, с именами файлов разобрались. Но что же нам положить в эти файлы? Вот теперь-то мы и переходим собственно к основной части сегодняшнего разговора. В самом начале файла стоит вставить код включения ядра движка. Подобное обращение на языке PHP выглядит следующим образом:
В этом файле содержатся те самые функции чтения-вывода, описанные в прошлой статье. Таким образом, они теперь становяться доступными для использования. В этом же файле стоит описать ещё некоторые полезные функции. Например, функция непосредственного получения какого-либо файла в виде строки (может пригодится):
Новостная система.Ещё одной полезностью может оказаться функция для организации простейшей новостной системы. Но, не смотря на простоту реализации, она имеет достачно удобные фичи, такие как вывод в любом месте страницы блока с указанным количеством последних новостей и возможность организации архива новостей. Суть её работы сводится к следуещему. Имеется текстовый файл с новостями, разделенными символом перевода строки (словом, каждая новость — в новой строке). Каждая строка разделена символом вертикальной черты («|») на два поля: дату и, собственно, саму новость. Опредилив функцию новостной системы в нашем включамом файле («ядре»), мы получаем возможность на любой странице получить нужное количество последних новостей. Первым параметром передаётся часть пути, указывающая на размещение файла с новостями. Количество выводимых новостей, как вы уже догадались, задаётся вторым, необязательным, параметром. Вот моя реализация функции новостной системы:
Что ж, на сегодня пока что всё. Продолжение следует... |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
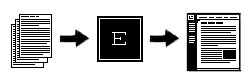
- Как сделать свой сайт привлекательным для поисковиков (Ранг: 3 )
- Эффективность использования чатов для сайта (Ранг: 2 )
- Основы SEO продвижения для сайтов (Ранг: 2 )
- Разработка сайта для доставки: ключевые аспекты создания и SEO-продвижения (Ранг: 2 )
- Онлайн игры для девочек: создавай свой бизнес и зарабатывай деньги (Ранг: 2 )
- Как использовать TikTok для продвижения своего бизнеса (Ранг: 2 )
- Преимущества создания чат-бота для сайта, мессенджера или социальных сетей (Ранг: 2 )